상속은 클라이언트 관점에서 인스턴스들을 동일하게 행동하는 그룹으로 믂고 싶을 때 사용해야 합니다. 단지 단순히 코드를 재사용하기 위함이 목적이면 안 됩니다!
다형성은 런타임에 메시지를 처리하기에 적합한 메서드를 동적으로 찾는 과정을 통해서 구현됩니다.
또 상속은 이런 메서드를 찾기 위한 탐색 경로를 클래스 계층의 형태로 구현하기 위한 방법입니다.
상속의 관점에서 다형성이 구현되는 기술적인 매커니즘을 먼저 살펴봅시다.
다형성
다형성(Polymorphism)은 여러 타입을 대상으로 동작할 수 있는 코드를 작성할 수 있는 방법입니다.
객체지향 프로그래밍에서 다형성은 아래처럼 분류될 수 있습니다.

오버로딩 다형성: 하나의 클래스 안에 동일한 메서드 존재하는 경우입니다. 흔히 말하는 메서드 오버로딩이 이 경우이죠.
강제 다형성: 언어가 지원하는 자동 타입 변환이나, 사용자가 직접 구현한 타입 변환을 이용해서 동일한 연산자가 다양한 타입에 사용할 수 있는 방식입니다. 예를 들면 연산자 오버로딩같은 경우가 있겠죠. Int 타입에 + 연산자를 사용하면 두 수를 더한 값이 되지만 String 타입에 + 연산자를 사용하면 두 문자열을 붙이는 연결 연산자가 됩니다.
매개변수 다형성: 클래스의 인스턴수 변수나, 메서드의 매개변수 타입을 임의 타입으로 선언한 후 사용하는 시점에 구체적인 타입으로 지정하는 방식입니다. 이는 제네릭 프로그래밍과 관련이 높습니다. 자바의 Collection 의 경우 대부분이 원소의 타입을 제네릭 T 로 해둔 것이 이 경우이죠.
포함 다형성: 메시지가 동일하더라도 수신한 객체의 타입에 따라 행동이 다르게 수행되는 것입니다. 서브타입 다형성이이라고도 합니다. 대부분 다형성이라고 하면 포함 다형성을 말합니다.
상속의 양면성
상속 역시 데이터와 행동을 객체라고 불리는 하나의 실행 단위 안으로 통합하는 객체지향 패러다임의 근본을 따라야 합니다.
상속을 사용하면 부모 클래스에서 정의한 모든 데이터, 행동을 자식 클래스에서 마치 자신의 것처럼 사용할 수 있습니다. 이것을 보면 상속은 코드 재사용을 위해 사용하는 것처럼 보이지만 실제로는 그것이 주 목적이 아닙니다.
상속을 사용한 강의 평가
수강생들의 성적을 계산하는 간단한 예제 프로그램을 구현해봅시다.
Lecture 클래스
public class Lecture {
private int pass;
private String title;
private List<Integer> scores = new ArrayList<>();
public Lecture(String title, int pass, List<Integer> scores) {
this.title = title;
this.pass = pass;
this.scores = scores;
}
public double average() {
return scores.stream().mapToInt(Integer::intValue).average().orElse(0);
}
public List<Integer> getScores() {
return Collections.unmodifiableList(scores);
}
public String evaluate() {
return String.format("Pass:%d Fail:%d", passCount(), failCount());
}
private long passCount() {
return scores.stream().filter(score -> score >= pass).count();
}
private long failCount() {
return scores.size() - passCount();
}
}
Grade 클래스
등급의 이름과 각 등급 범위의 최소, 최대 성적을 인스턴스 변수로 가집니다.
public class Grade {
private String name;
private int upper,lower;
private Grade(String name, int upper, int lower) {
this.name = name;
this.upper = upper;
this.lower = lower;
}
public String getName() {
return name;
}
public boolean isName(String name) {
return this.name.equals(name);
}
public boolean include(int score) {
return score >= lower && score <= upper;
}
}
GradeLecture 클래스
Lecture 클래스를 상속받아서 Lecture 출력 결과에 등급별 통계를 추가하는 기능을 더합니다.
public class GradeLecture extends Lecture {
private List<Grade> grades;
public GradeLecture(String name, int pass, List<Grade> grades, List<Integer> scores) {
super(name, pass, scores);
this.grades = grades;
}
@Override
public String evaluate() {
return super.evaluate() + ", " + gradesStatistics();
}
private String gradesStatistics() {
return grades.stream().map(grade -> format(grade)).collect(joining(" "));
}
private String format(Grade grade) {
return String.format("%s:%d", grade.getName(), gradeCount(grade));
}
private long gradeCount(Grade grade) {
return getScores().stream().filter(grade::include).count();
}
public double average(String gradeName) {
return grades.stream()
.filter(each -> each.isName(gradeName))
.findFirst()
.map(this::gradeAverage)
.orElse(0d);
}
private double gradeAverage(Grade grade) {
return getScores().stream()
.filter(grade::include)
.mapToInt(Integer::intValue)
.average()
.orElse(0);
}
}
메서드 오버라이딩: 자식 클래스 안에 상속받은 메서드와 동일한 시그니처의 메서드를 재정의해서 부모 클래스의 구현을 새로운 구현으로 대체하는 것. 위에서는 evaluate 메서드가 그렇겠네요.
메서드 오버로딩: 자식 클래스에 부모 클래스에서 정의한 메서드와 동일한 이름, 다른 시그니처를 가진 메서드를 추가하는 것. 위에서는 average 메서드가 메서드 오버로딩입니다.
이렇게 상속을 설명할 예제가 준비되었습니다. 이제 데이터 관점의 상속과 행동 관점의 상속이 가지는 특성을 알아봅시다.
데이터 관점의 상속
Lecture 인스턴스를 아래처럼 생성했을 때의 그림입니다.
Lecture lecture = new Lecture("객체지향 프로그래밍", 70, Arrays.asList(81, 95, 75, 50, 45));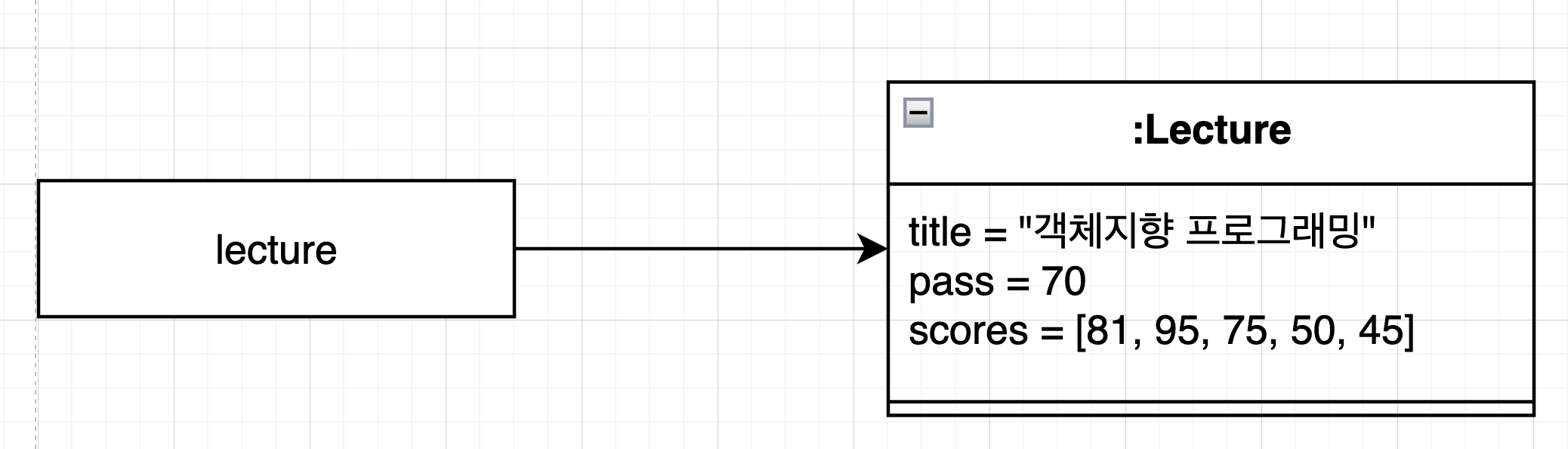
만악 GradeLecture 인스턴스를 생성했다면,
Lecture lecture = new GradeLecture("객체지향 프로그래밍", 70,
Arrays.asList(new Grade("A", 100, 95),
new Grade("B", 94, 80),
....
)),
Arrays.asList(80, 95, 75, 50, 45));아래 그림처럼 표현될 것입니다.
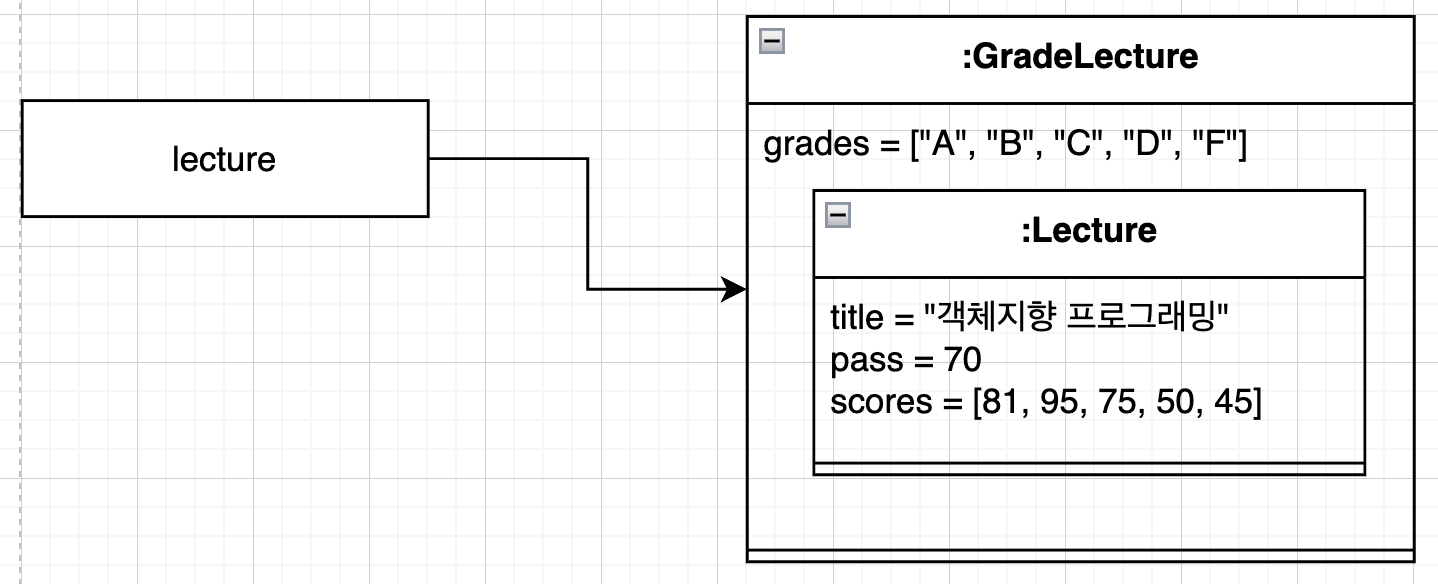

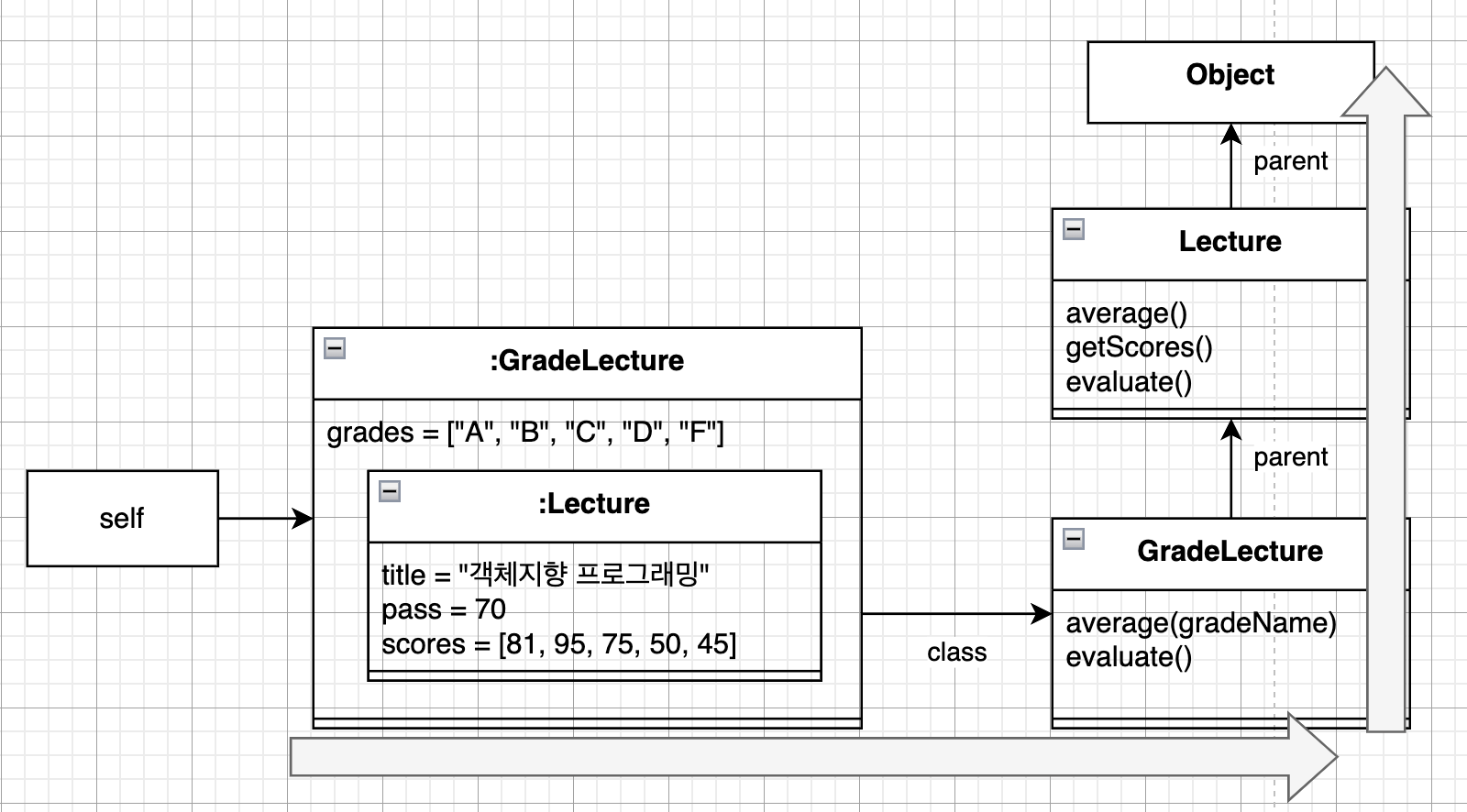
즉, 데이터 관점에서 상속은 자식 클래스의 인스턴스 안에서 부모 클래스의 인스턴스를 포함하는 것으로 볼 수 있습니다.
행동 관점의 상속
부모 클래스의 모든 퍼블릭 메서드는 자식 클래스의 퍼블릭 인터페이스에 포함됩니다.
하지만 실제로 클래스의 코드가 합쳐지거나 복사하는 작업이 수행되는 것이 아닙니다. 런타임에 시스템이 자식 클래스에 정의되지 않은 메서드가 있으면 이 메서드를 부모 클래스 안에서 찾습니다.
객체는 각 인스턴스별로 독립적인 메모리를 할당받지만, 클래스는 한 번만 메모리에 로드됩니다. 각 인스턴스별로 클래스를 가리키는 포인터를 갖게 됩니다. 아래 그림처럼 말이죠.
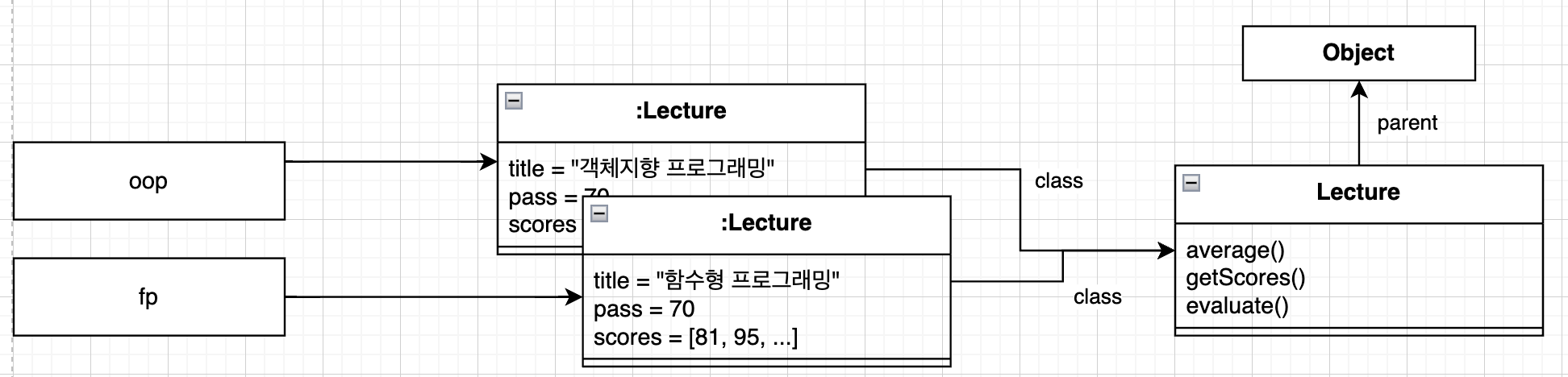
화살표로 포인터가 표현되어 있습니다. 이 포인터를 이용해서 상속 계층을 따라 부모 클래스의 정의로 이동할 수 있습니다.
메시지를 수신한 객체는 class 포인터로 연결된 자신의 클래스에서 적절한 메서드를 찾고, 없다면 클래스의 parent 포인터를 따라서 부모 클래스를 차례대로 훑어 가면서 적절한 메서드가 존재하는지 검색합니다.
그렇다면 GradeLecture 클래스의 인스턴스를 생성했을 때의 메모리 구조를 봅시다.
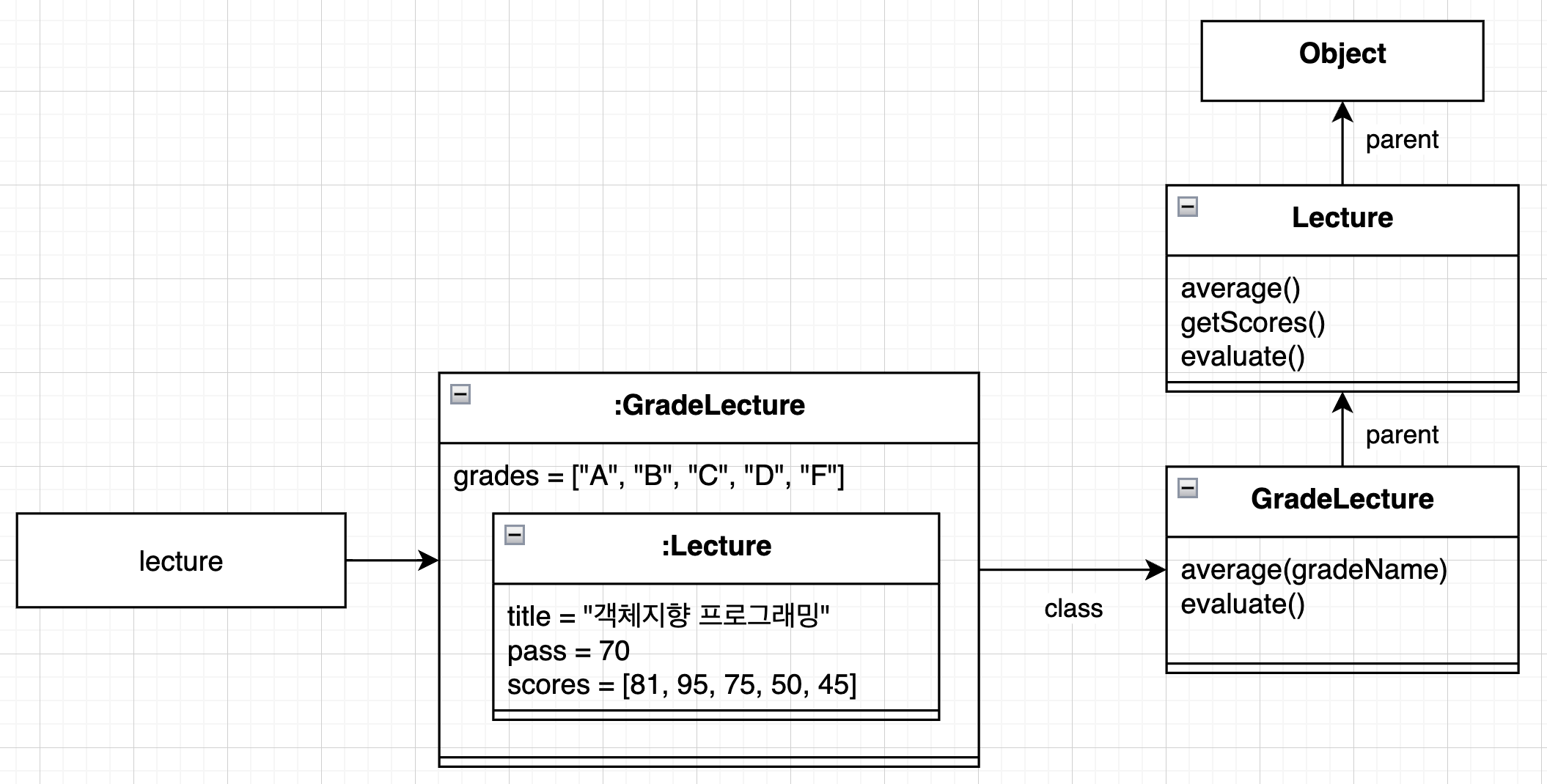
물론 이 그림은 상속의 개념적인 그림일 뿐, 구체적인 구현 방법이나 메모리 구조는 언어, 플랫폼에 따라 다릅니다.
업캐스팅과 동적 바인딩
같은 메시지, 다른 메서드
지금까지 작성한 성적 계산 프로그램에 각 교수별로 강의에 대한 성적 통계를 계산하는 기능을 추가해 봅시다.
통계 계산 책임은 Professor 가 가집니다.
public class Professor {
private String name;
private Lecture lecture;
public Professor(String name, Lecture lecture) {
this.name = name;
this.lecture = lecture;
}
public String compileStatistics() {
return String.format("[%s] %s - Avg: %.1f", name,
lecture.evaluate(), lecture.average());
}
}
Professor 클래스의 두번째 인스턴스 변수 lecture 는 Lecture 타입이므로 Lecture 의 인스턴스를 전달해도 되며, GradeLecture 의 인스턴스를 전달해도 됩니다.
마찬가지로 compileStatistics() 메서드를 실행할 때 Lecture 클래스의 evaluate() 메서드가 실행되도 괜찮고, GradeLecture 클래스의 evalutate() 메서드가 실행되도 괜찮습니다.
이렇게 코드 안에서 선언된 참조 타입과 무관하게 실제로 메시지를 수신하는 객체의 타입에 따라 실행되는 메서드가 달라질 수 있다는 것은 업캐스팅과 동적 바인딩이라는 매커니즘 때문입니다.
업캐스팅 → 부모 클래스 타입으로 선언된 변수에서 자식 클래스의 인스턴스를 할당하는 것이 가능하다.
동적 바인딩 → 선언된 변수의 타입이 아닌 메시지를 수신하는 객체의 타입에 따라 실행되는 메서드가 결정된다. 객체지향에서는 메시지를 처리할 구체적인 메서드는 런타임에 결정되기 때문이다.
업캐스팅과 동적 메서드 탐색은 코드를 변경하지 않고도 기능을 추가할 수 있게 해주는 OCP(개방-폐쇄 원칙)의 의도와 일치합니다.
업캐스팅
모든 객체지향 언어는 명시적으로 타입을 변환하지 않고도 부모 클래스 타입의 참조 변수에 자식 클래스의 인스턴스를 대입할 수 있게 해줍니다.
Lecture lecture = new GradeLecture(....);부모 클래스 타입으로 선언된 파라미터에 자식 클래스의 인스턴스를 전달하는 것도 가능합니다.
public class Professor {
public Professor(String name, Lecture lecture) { ... }
}
Professor professor = new Professor("다익스트라", new GradeLecture(...));
반대로 부모 클래스의 인스턴스를 자식 클래스 타입으로 변환하기 위해서는 명시적인 타입 캐스팅이 필요합니다. 이를 다운 캐스팅이라고 합니다.
Lecture lecture = new GradeLecture(...);
GradeLecture gradeLecture = (GradeLecture)lecture;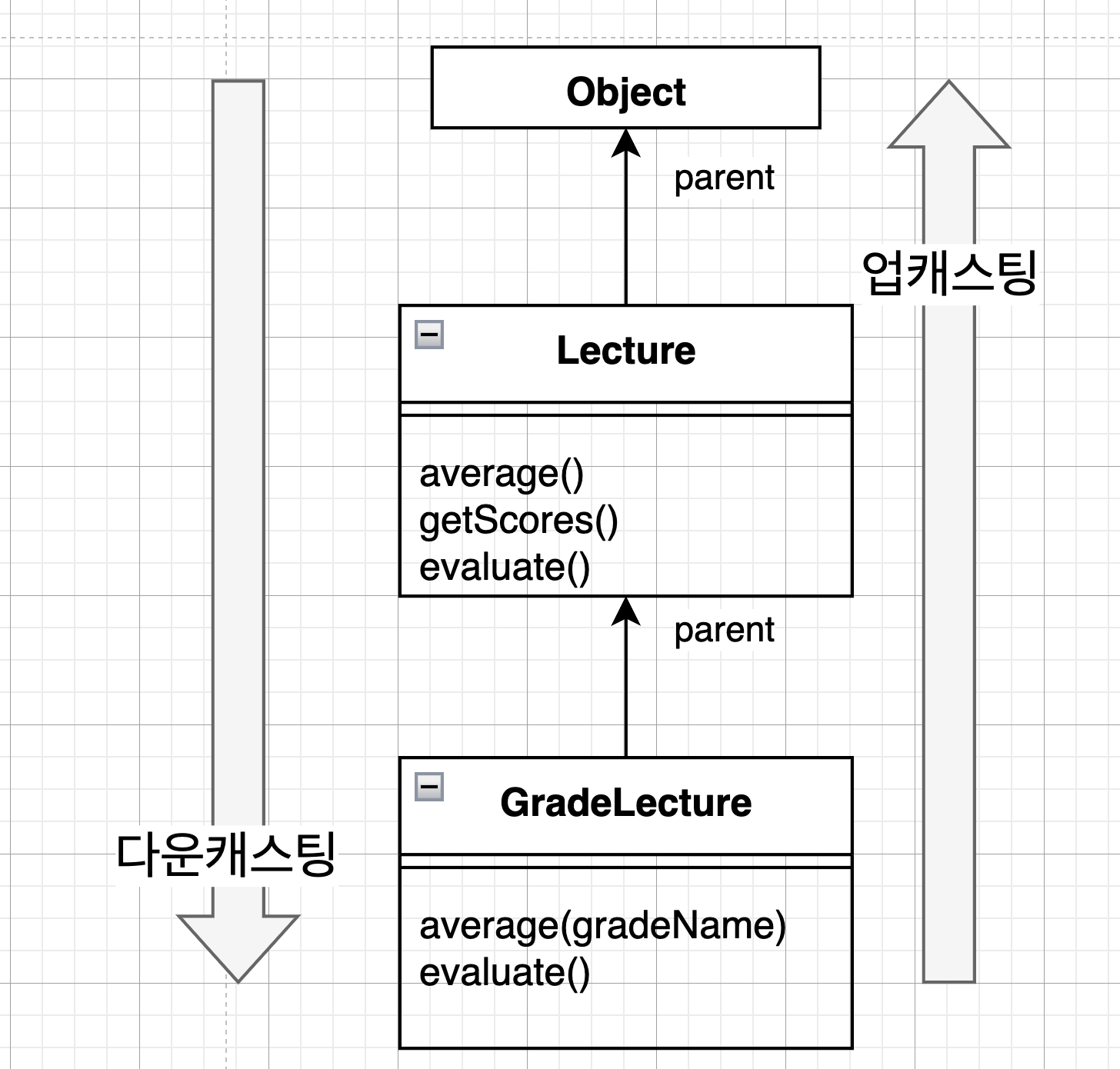
자식 클래스는 아무런 제약 없이 부모 클래스를 대체할 수 있기 때문에 부모 클래스와 협력하는 클라이언트는 다양한 자식 클래스의 인스턴스와도 협력할 수 있습니다.
즉, Professor 는 Lecture 를 상속받는 어떤 자식 클래스와도 협력할 수 있는 무한한 확장 가능성을 가집니다. 유연하고 확장이 용이한 설계입니다.
동적 바인딩
객체지향 언어에서 메서드를 실행하는 방법은 메시지를 전송하는 것입니다.
이 메시지를 처리할 수 있는 메서드를 런타임에 결정하는 방식을 동적 바인딩(dynamic binding) 또는 지연 바인딩(late binding) 이라고 합니다.
Professor 의 complileStatistics 메서드는 정확히 어떤 클래스에 정의되어 있는 evaluate 메서드를 실행할지 코드 상으로는 알 수 없습니다.
동적 메서드 탐색과 다형성
객체지향 시스템은 아래 규칙에 따라서 실행할 메서드를 선택합니다.
- 메시지를 수신한 객체는 먼저 자신을 생성한 클래스에 적합한 메서드가 있는지 검사함. 찾으면 실행하고 탐색 종료.
- 찾지 못하면 부모 클래스에서 메서드 탐색을 계속해서 검사함. 찾을 때까지 상속 계층을 따라 올라가며 게속 검사.
- 최상위 클래스까지 찾지 못하면 예외를 발생시키며 탐색을 중단.
객체가 메시지를 수신하면 컴파일러는 self 참조 라는 임시 변수를 자동으로 생성하고 메시지를 수신한 객체를 가리키도록 설정합니다. 상속 계층을 위로 올라가면서 동적 메서드 탐색을 하다가 메서드 탐색이 종료되면 self 참조는 소멸됩니다.
정적 타입 언어인 C++, 자바, C# 에서는 self 참조를 this 키워드로 사용합니다.. 동적 타입 언어인 스몰토크, 루비에서는 self 참조를 self 키워드를 사용합니다. 파이썬도 self 를 사용하지만 임의로 참조 이름을 정할 수도 있습니다.
동적 메서드 탐색은 자동적인 메시지 위임 과 동적인 문맥 을 사용하여 메서드를 탐색합니다.
자식 클래스가 자신이 이해할 수 없는 메시지를 전송받으면 상속 계층을 따라 부모 클래스에게 처리를 위임합니다.
메시지를 수신했을 때 실제로 어떤 메서드를 실행할지는 런타임에 이루어지며, 메서드 탐색 경로는 self 참조를 이용해서 결정합니다.
자동적인 메시지 위임
상속을 이용할 경우 프로그래머가 메시지 위임과 관련된 코드를 명시적으로 작성할 필요가 없습니다. 상속 계층을 따라 자동으로 부모 클래스에게 위임됩니다.
메서드 오버라이딩
Lecture lecture = new Lecture(...);
lecture.evaluate();Lecture lecture = new GradeLecture(...);
lecture.evaluate();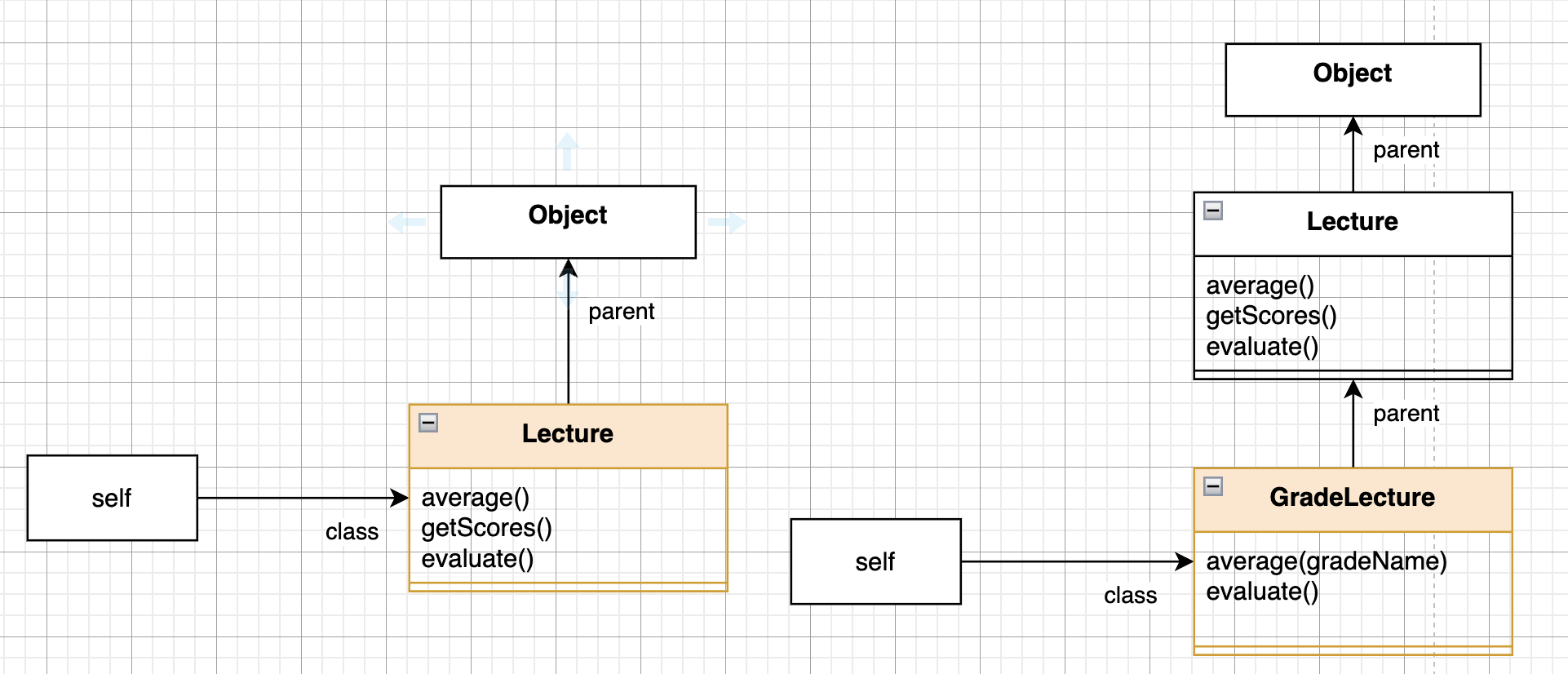
new Lecture(...) 의 경우 Lecture 클래스 안에 evaluate 메서드가 존재하기 때문에 시스템은 이 메서드를 실행한 후 탐색을 종료합니다.
new GradeLecture(...) 의 경우 자식 클래스와 부모 클래스 양쪽 모두에 동일한 시그니처를 가진 메서드가 구현되어 있다면 자식 클래스의 메서드가 먼저 검색됩니다.
따라서 자식 클래스의 메서드가 부모 클래스의 메서드를 감추는 것처럼 보입니다.
메서드 오버로딩
GradeLecture lecture = new GradeLecture(...);
lecture.average("A");Lecture lecture = new GradeLecture(...);
lecture.average();첫번째로 average(String gradeName) 메서드를 호출하는 경우 메시지를 처리할 수 있는 average 메서드가 GradeLecture 클래스에서 발견되어 이 클래스에서 메서드 탐색이 종료됩니다.
반면에 average() 메서드를 호출하는 경우 메시지를 처리할 수 있는 average 메서드는 GradeLecture 클래스 안에 없습니다. 그래서 부모 클래스인 Lecture 클래스까지 메서드 탐색이 올라가서 Lecture 클래스의 average 메서드가 실행됩니다.
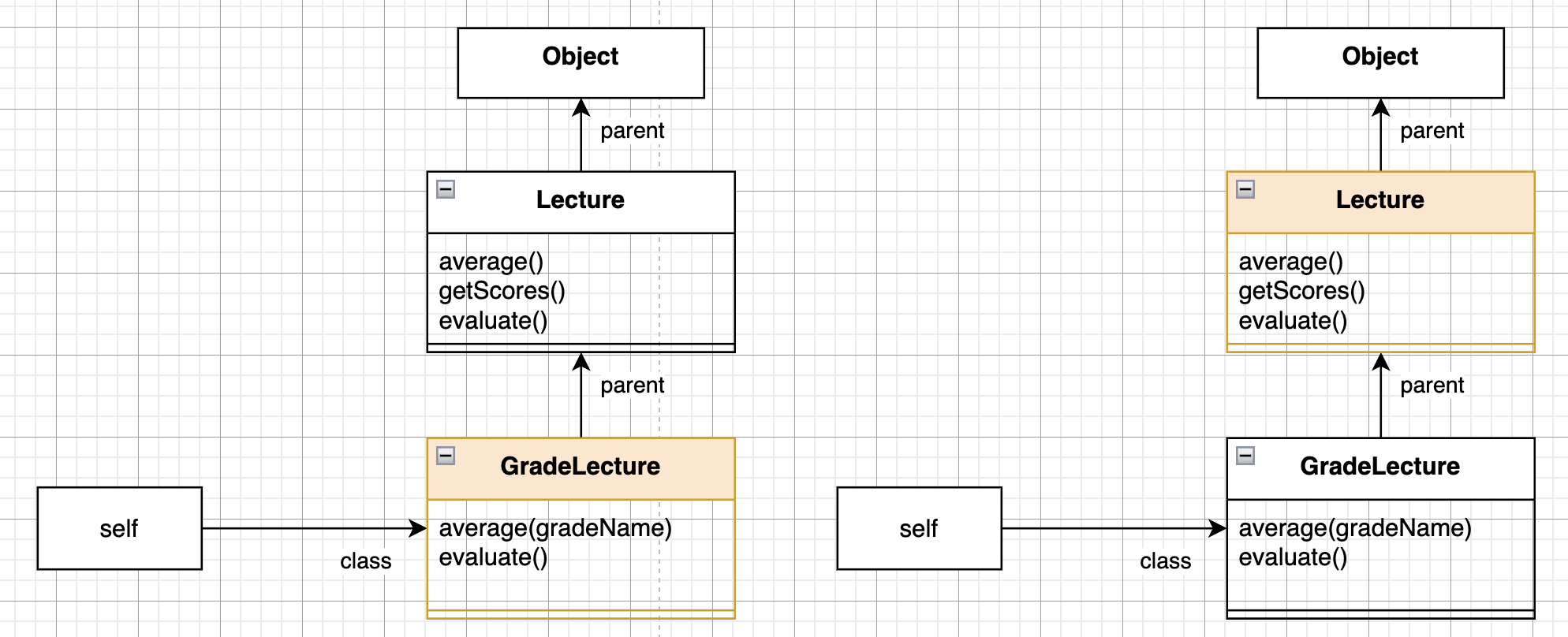
메서드 오버라이딩은 자식 클래스가 부모 클래스에 존재하는 메서드와 동일한 시그니처를 가진 메서드를 재정의해서 부모 클래스의 메서드를 감추는 것이었습니다.
하지만 이 경우 average() 메서드와 avergae(String gradeName) 메서드는 시그니처가 다릅니다. 이렇게 동일한 이름의 메서드가 공존하는 경우를 메서드 오버로딩이라고 합니다.
메서드 오버라이딩은 상위 클래스의 메서드를 감추지만 메서드 오버로딩은 공존합니다. 클라이언트는 오버로딩된 모든 메서드를 호출할 수 있습니다.
일부 언어(C++)는 상속 계층 사이에서의 메서드 오버로딩을 지원하지 않습니다.
이는 상속 계층에서 동일한 이름을 가진 메서드가 공존해서 생기는 혼란을 방지하기 위해 지원하지 않는 것인데 이를 이름 숨기기(name hiding) 이라고 부릅니다.
이런 경우는 부모 클래스에 정의된 모든 메서드를 자식 클래스에서 오버라이딩해야 합니다.
동적 메서드 탐색과 관련된 규칙은 언어마다 다를 수 있습니다.
동적인 문맥
이렇게 메시지를 수신한 객체가 무엇이냐에 따라 메서드 탐색을 위한 문맥이 동적으로 바뀝니다. 메시지를 수신한 객체를 가리키는 self 참조가 동적인 문맥을 결정합니다.
self 참조가 자신에게 다시 메시지를 전송하는 경우도 있습니다. 이를 self 전송(self send) 라고 합니다.
self 전송은 현재 클래스의 메서드를 호출하는 것이 아닌 현재 객체에게 메시지를 전송하는 것입니다.
여기서 객체는 self 참조가 가리키는 객체입니다.
코드를 통해 자세히 봅시다. Lecture, GradeLecture 클래스에 평가 기준에 대한 정보를 리턴하는 stats 메서드를 추가합시다. Lecture 클래스에서는 stats 메서드 안에서 자신의 getEvaluationMethod 메서드를 호출합니다.
public class Lecture {
// ...
public String stats() {
return String.format("Title: %s, Evaluation Method: %s",
title, getEvaluationMethod());
}
public String getEvaluationMethod() {
return "Pass or Fail";
}
}
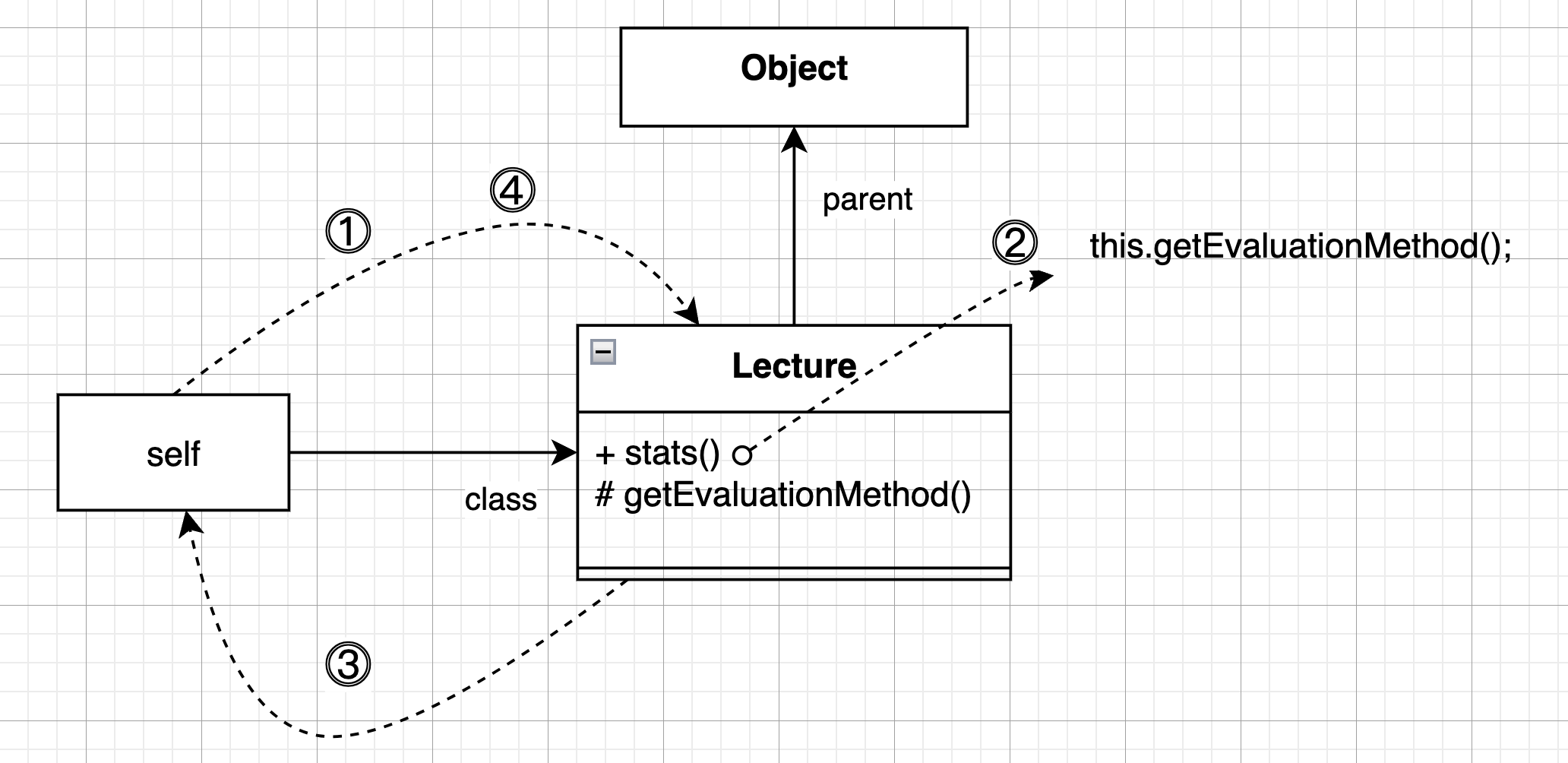
Lecture 인스턴스가 stats 메시지를 수신하면 self 참조는 메시지를 수신한 Lecture 인스턴스를 가리키도록 자동으로 할당됩니다.
시스템은 이 객체의 클래스인 Lecture 에서 stats 메서드를 찾아서 실행시킵니다.
stats 메서드를 실행하던 중 getEvaulationMethod 메서드 호출 구문을 찾으면 시스템은 self 참조가 가리키는 현재 객체에게 메시지를 전송해야 한다고 판단합니다. 결과적으로 stats 메시지를 수신한 동일한 객체에게 getEvaulationMethod 메시지를 전송할 것입니다.
즉, self 참조가 가리키는 Lecture 클래스에서부터 다시 메서드 탐색이 시작되고 Lecture 의 getEvaulationMethod 메서드를 실행한 후 메서드 탐색을 종료합니다.
그렇다면 여기에 상속이 끼어든다면 어떻게 될까요?
이번에는 GradeLecture 클래스에서 아래처럼 getEvaulationMethod 메서드를 오버라이드해봅시다.
public class GradeLecture extends Lecture {
// ....
@Override
public String getEvaluationMethod() {
return "Grade";
}
}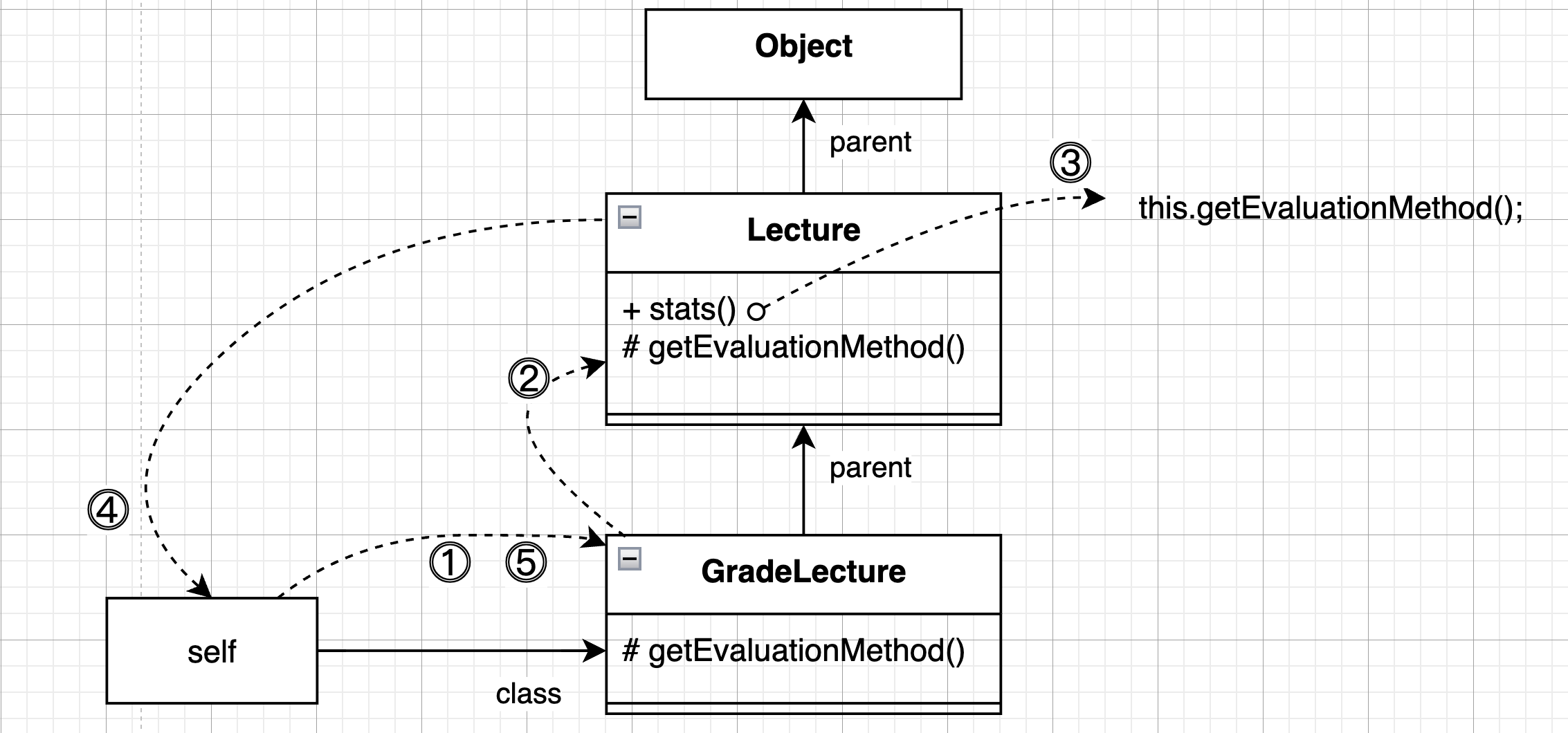
GradeLecture 에 stats 메시지를 전송하면 self 참조는 GradeLecture 의 인스턴스를 가리키도록 설정됩니다. 메서드 탐색은 GradeLecture 클래스에서부터 시작됩니다.
GradeLecture 클래스에는 stats 메시지를 처리할 수 있는 적절한 메서드가 존재하지 않기 때문에 부모 클래스인 Lecture 에서 메서드 탐색을 계속하고 Lecture 클래스의 stats 메서드를 찾아서 실행합니다.
stats 메서드를 실행하는 중에 self 참조가 가리키는 객체에게 getEvaluationMethod 메시지를 전동하는 구문을 만나서 self 참조가 가리키는 객체에서부터 메서드 탐색을 합니다.
여기서 self 참조가 가리키는 객체는 GradeLecture 의 인스턴스입니다. 따라서 다시 GradeLecture 에서부터 메시지 탐색을 합니다.
이렇게 되면 시스템은 GradeLecture 클래스에서 getEvaluationMethod 메서드를 찾아서 실행하고 메서드 탐색을 종료합니다.
결과적으로 Lecture 클래스의 stats 메서드와 GradeLecture 클래스의 getEvaluationMethod 메서드의 실행결과를 조합한 문자열이 리턴됩니다.
이렇게 self 전송이 깊은 상속 게층과 계층 중간에 숨겨져 있는 메서드 오버라이딩과 만나면 이해하기 어려운 코드가 만들어집니다.
이해할 수 없는 메시지
만약 상속 계층의 최 상위로 왔는데 메시지를 처리할 수 없다는 사실을 알게 되면, 즉, 객체가 메시지를 이해할 수 없다면 어떻게 할까요?
정적 타입 언어와 이해할 수 없는 메시지
정적 타입 언어에서는 컴파일 시 상속 계층 안의 클래스들이 메시지를 이해할 수 있는지 판단합니다. 만약 불가능하다면 컴파일 에러가 발생합니다.
동적 타입 언어와 이해할 수 없는 메시지
동적 타입 언어에서는 컴파일 단계가 존재하지 않기 때문에 코드 실행 전에는 메시지 처리 가능 여부를 판단할 수 없습니다.. 즉, 런타임에서야 알 수 있게 됩니다.
스몰토크 언어의 경우 메시지를 찾지 못하면 self 참조가 가리키는 현재 객체에게 이해할 수 없다는 메시지 doesNotUnderstand 메시지를 전송하고 루비의 경우 method_missing 메시지를 전송합니다.
이 메시지 역시 self 참조가 가리키는 객체의 클래스에서부터 시작해서 메서드를 탐색합니다. 상속 계층 안의 어떤 클래스도 메시지 처리를 할 수 없다면 다시 최상위 클래스에서 최종적으로 예외를 던집니다. 스몰토크의 최상위 클래스 Object 는 doesNotUnderstand 메시지에 대한 처리로 MessageNotUnderstood 예외를 더닞고, 루비는 method_missing 메시지에 대한 처리로 NoMethodError 예외를 던집니다.
하지만 다른 방법도 있습니다. doesNotUnderstand 나 method_missing 메시지에 응답할 수 있는 메서드를 따로 구현하면, 객체는 자신의 인터페이스에 정의되지 않은 메시지를 처리하는 것이 가능해집니다.
이 경우 객체가 해당하는 메서드를 구현하던지, method_missing 메서드를 재정의하던지 상관없이 클라이언트는 단지 전송한 메시지가 처리된다는 사실만 알게 됩니다. 즉, 더 순수한 관점에서 객체 지향 패러타임을 구현하는 것입니다. 메시지 전송자는 자신이 원하는 메시지를 전송하고 수신자는 스스로 판단하여 메시지를 처리하는 것이죠. 메시지 인터페이스와 메시지를 구체적으로 처리하는 메서드 구현이 분리된 것입니다.
물론 이러한 특성 때문에 코드 이해와 수정이 어려우며 디버깅 과정도 어렵습니다.
정적 타입 언어는 유연성이 조금 떨어지지만 더 쉽고 안정적입니다.
self 대 super
self 참조는 동적입니다. 이런 특성과 대비해서 super 참조가 있습니다.
자식 클래스에서 부모 클래스의 구현을 재사용할 때 super 참조라는 내부 변수를 제공합니다.
public class GradeLecture extends Lecture {
// ...
@Override
public String evaluate() {
return super.evaluate() + ", " + gradesStatistics();
}
}'메서드를 호출' 하는 것이 아닌 super 참조를 이용해 '메시지를 전송' 합니다. super.evaluate() 에 의해 호출되는 메서드는 부모 클래스의 메서드가 아닌 더 상위의 조상 클래스의 메서드일 수 있습니다.
예를 들어 FormattedGradeLecture 라는 GradeLecture 클래스의 자식 클래스를 만들어 봅시다.
public class FormattedGradeLecture extends GradeLecture {
public FormattedGradeLecture(String name, int pass, List<Grade> grades, List<Integer> scores) {
super(name, pass, grades, scores);
}
public String formatAverage() {
return String.format("Avg: %1.1f", super.average());
}
}
super 는 상속 계층을 거슬러 올라가 가장 가까운 상위 클래스의 메서드가 실행됩니다.
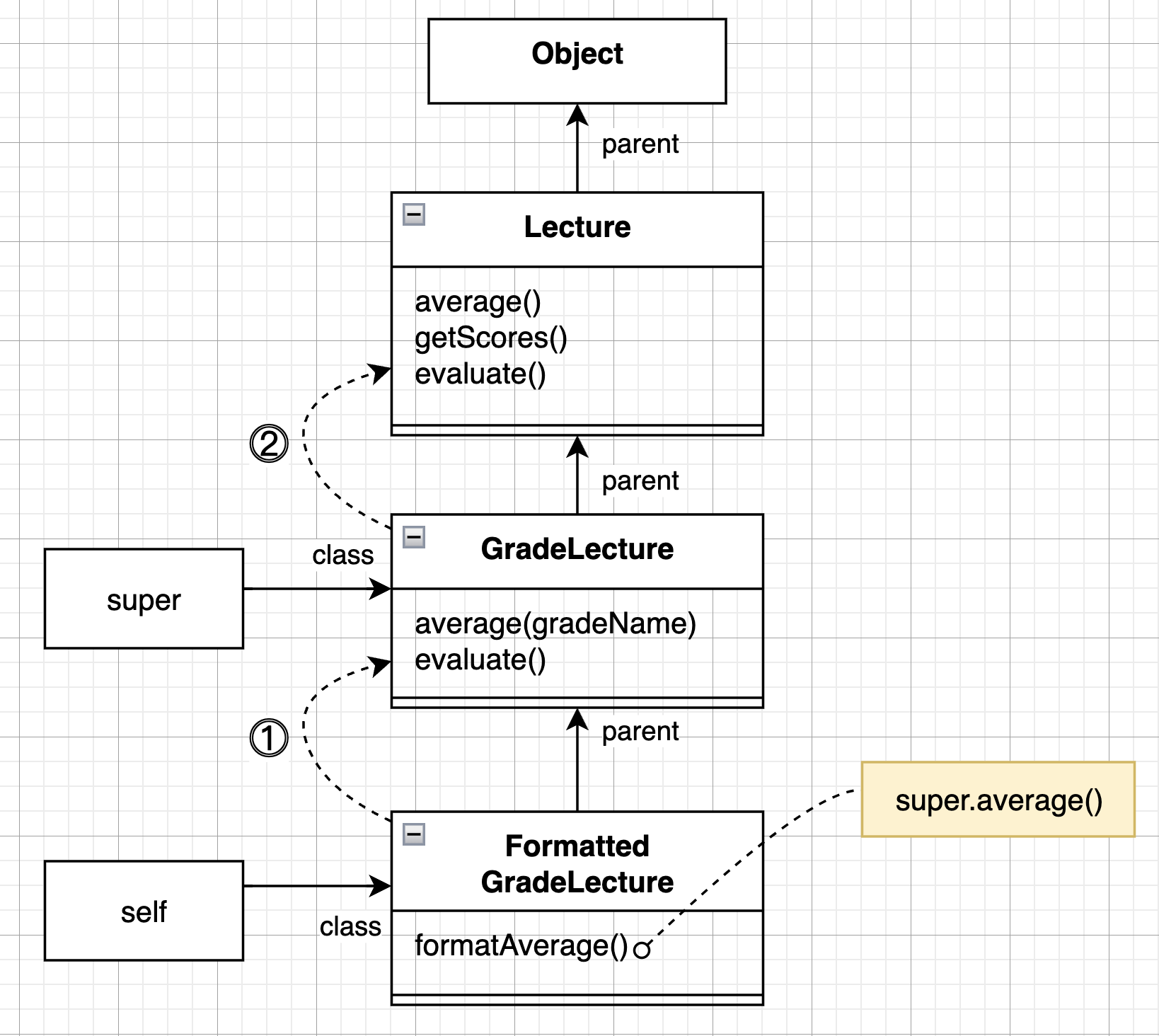
super 참조의 용도는 부모 클래스에 정의된 메서드를 실행하는 것이 아니라
'지금 이 클래스의 부모 클래스에서부터 메서드 탐색을 시작하세요' 입니다.
super 참조를 통해 메시지를 전송하는 것은 마치 부모 클래스의 인스턴스에게 메시지를 전송하는 것처럼 보이기 때문에 super 전송(super send) 라고 합니다.
자바는 super 참조를 위해 super 라는 예약어, C# 에서는 base 라는 예약어, C++ 의 경우 부모 클래스의 이름과 범위 지정 연산자인 :: 를 조합해서 부모 클래스에서부터 메서드 탐색을 시작할 수 있습니다.
self 전송은 메시지를 수신하는 객체의 클래스에 따라 메서드 탐색의 시작 위치가 동적으로 결정되고(런타임에 결정됨), super 전송은 항상 메시지를 전송하는 클래스의 부모 클래스에서부터(컴파일 타임에 결정됨) 시작됩니다.
스칼라의 트레이트는 super 의 대상이 런타임에 결정될 수 있음. 하지만 대부분은 super 가 컴파일타임에 결정됨.
상속 대 위임
다형성은 self 참조가 가리키는 현재 객체에게 메시지를 전달하는 특성을 기반으로 합니다. 이로 인해 자식 클래스에서 부모 클래스로 self 참조를 전달하는 매커니즘으로 상속이 동작합니다.
위임과 self 참조
self 참조는 항상 메시지를 수신한 객체를 가리킵니다. 따라서 메서드 탐색 중에는 자식 클래스의 인스턴스와 부모 클래스의 인스턴스가 동일한 self 참조를 공유한다고 볼 수 있습니다.
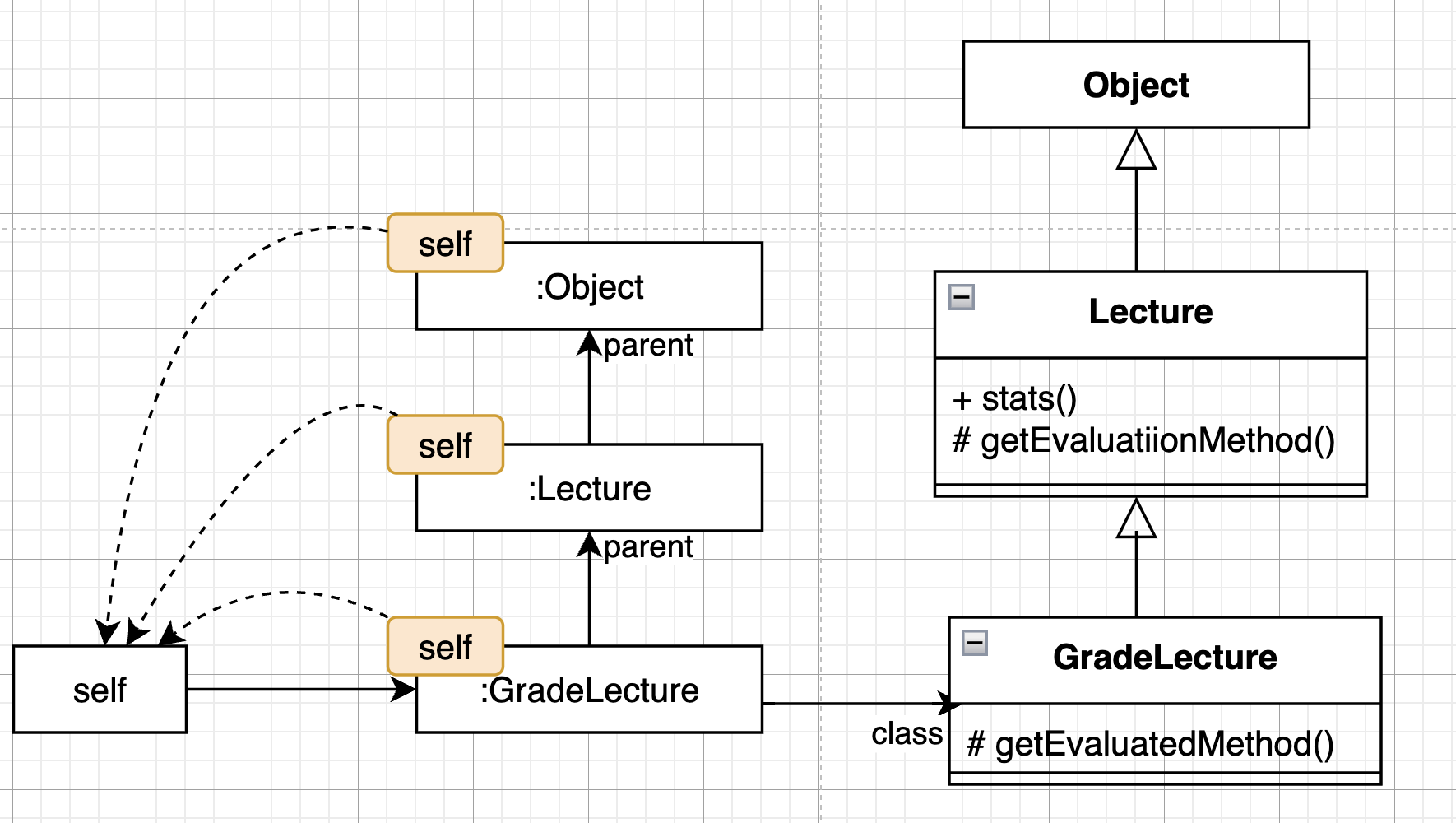
GradeLecture 에서 Lecture 로 self 참조가 공유되는 과정을 상속을 사용하지 않고 루비 언어를 사용해서 코드로 구현하면 아래와 같습니다.
class Lecture
def initialize(name, scores)
@name = name
@scores = scores
end
def stats(this)
"Name: #{@name}, Evaluation Method: #{this.evaluationMethod(this)}"
end
def getEvaluationMethod()
"Pass or Fail"
end
end
stats 메서드의 인자로 this 를 전달받습니다. this 에는 메시지를 수신한 객체를 가리키는 self 참조가 보관됩니다. (루비에서는 self 가 예약어이므로 this 를 사용함)
모든 객체지향 언어는 자동으로 self 참조를 생성하고 할당하기 때문에 실제로는 위처럼 this 를 파라미터로 받을 필요가 없습니다. 단지 self 참조가 상속 계층을 따라 전달되는 것을 보이기 위해 인위적으로 this 를 전달하고 있습니다.
stats 메서드에서 this에게 evaulationMethod 메시지를 전송합니다. 실제 실행되는 메서드는 Lecture 의 getEvaluationMethod 메서드가 아닐 수 있다는 것을 보이고 있습니다. this 에 전달되는 객체에 따라 실제 메서드가 달라지겠죠.
lecture = Lecture.new("OOP", [1,2,3])
puts lecture.stats(lecture)이렇게 코드를 작성하면 객체가 실행될 문맥인 lecture 를 stats 메서드의 인자로 전달합니다. 그러면 Lecture 의 stats 메서드가 실행되어서 this.getEvaluationMethod() 실행 -> Lecture 의 getEvaluationMethod 메서드가 실행될 것입니다.
class GradeLecture
def initialize(name, canceled, scores)
@parent = Lecture.new(name, scores)
@canceled = canceled
end
def stats(this)
@parent.stats(this)
end
def getEvaluationMethod()
"Grade"
end
end
위 GradeLecture 코드는 실제 상속 관계 구문을 사용하지 않고 자식 클래스의 인스턴스가 부모 클래스의 인스턴스에 대한 링크를 포함하는 것으로 상속 관계를 흉내내고 있습니다.
grade_lecture = GradeLecture.new("OOP", false, [1,2,3])
puts grade_lecture.stats(grade_lecture)
이렇게 GradeLecture 의 인스턴스를 직접 전달해서 GradeLecture 의 stats 메서드를 호출하고 있습니다.
이 경우 동작이 결국 이렇게 되겠네요
- GradeLecture 는 인스턴스 변수인 @parent 에 Lecture 의 인스턴스를 생성해서 저장해서 이 링크를 통해 컴파일러가 제공해주던 동적 메서드 탐색 매커니즘을 직접 구현함.
- GradeLecture 의 stats 메서드는 추가적인 작업 없이 @parent 에게 요청을 그대로 전달하여 자식 클래스에 메서드가 없을 때 부모 클래스에서 메서드 탐색을 계속하는 동적 메서드 탐색 과정을 흉내냈다.
- GradeLecture 의 getEvaluationMethod 메서드는 stats 메서드처럼 요청을 @parent 에 전달하지 않고 자신만의 방법으로 메서드를 구현하고 있고 GradeLecture 의 외부에서는 Lecture 의 getEvaluationMethod 메서드가 감춰진다. 이는 상속에서의 메서드 오버라이딩과 동일하다.
- GradeLecture 의 stats 메서드는 인자로 전달된 this를 그대로 Lecture 의 stats 메서드에 전달하고 Lecture 의 stats 메서드는 인자로 전달된 this 에게 getEvaluationMethod 메시지를 전송하기 때문에 GradeLecture 의 getEvaluationMethod 메서드가 실행된다.
GradeLecture 의 stats 메서드는 직접 메시지를 처리하지 않고 Lecture 의 stats 메서드에게 요청을 전달합니다.
이렇게 자신이 수신한 메시지를 다른 객체에게 동일하게 전달해서 처리를 요청하는 것을 위임(delegation) 이라고 합니다.
위임은 자신이 정의하지 않거나 처리할 수 없는 속성 또는 메서드의 탐색 과정을 다른 객체로 이동시키기 위해 사용합니다.
이를 위해서 위임은 항상 현재 실행 문맥을 가리키는 self 참조를 인자로 전달합니다.
이것이 self 참조를 전달하지 않는 포워딩과 위임의 차이입니다.
위임의 정확한 용도는 클래스를 이용한 상속 관계를 객체 사이의 합성 관계로 대체해서 다형성을 구현하는 것입니다.
위임은 객체 사이의 동적인 연결관계를 이용해서 상속을 구현하는 방법입니다.
상속에서는 이렇게 직접 구현해야 하는 번잡한 관정을 자동으로 처리해줍니다. GradeLecture 를 Lecture 의 자식 클래스로 선언하면 실행 시에 인스턴스들 사이에서 self 참조가 자동으로 전달됩니다. 이 self 참조 전달은 자식 클래스의 인스턴스와 부모 클래스의 인스턴스 사이에 동일한 실행 문맥을 공유할 수 있게 합니다.
이렇게 클래스 기반의 객체지향 언어에서 객체 사이의 위임을 직접 구현하는 것은 꽤 어렵습니다.
프로토타입 기반의 객체지향 언어에는 클래스가 없고 오직 객체만 존재합니다. 그런데 우리는 클래스가 아닌 객체를 이용해서도 상속을 흉내낼 수 있다는 것을 방금 코드를 통해 알아냈습니다.
클래스가 없는 프로토 타입 기반 객체지향 언어에서도 (예를 들어 자바 스크립트) 객체 사이의 위임을 이용하여 상속을 구현할 수 있습니다. 자바 스크립트에서는 클래스가 존재하지 않기 때문에 오직 객체들 사이의 메시지 위임만을 이용해서 다형성을 구현합니다.
즉, 객체 지향 패러다임에서 클래스는 필수가 아니며 중요한 것은 메시지와 협력입니다.
클래스 없이도 객체 사이의 협력 관계를 구축할 수 있으며 상속 없이도 다형성을 구현하는 것이 가능합니다.
심지어 클래스 기반 객체지향 언어를 사용하더라도 클래스라는 제약을 벗어나기 위해서 위임 매커니즘을 사용할 수 있습니다.
'Computer Science > 객체지향' 카테고리의 다른 글
| 코드의 네이밍과 코딩 컨벤션은 왜 중요한가? (0) | 2024.02.20 |
|---|---|
| 서브클래싱과 서브타이핑 - 코드로 이해하는 객체지향 (0) | 2023.09.19 |
| 합성과 유연한 설계 - 코드로 이해하는 객체지향 (0) | 2023.09.19 |
| 상속과 코드 재사용. 상속을 사용할 때 조심해야 할 점을 중심으로 - 코드로 이해하는 객체지향 (0) | 2023.08.28 |
| 유연한 설계 - 코드로 이해하는 객체지향 (0) | 2023.08.26 |