OpenCL
OpenCL(Open Computing Language)는 개방형 범용 병렬 컴퓨팅 프레임워크이다. GPU, CPU, DSP 등의 프로세서로 이루어진 heterogenous 플랫폼에서 실행되는 프로그램을 작성할 수 있어 이식성이 높은 언어이다. 하나의 커널만 만들어도 각기 다른 플랫폼에서 사용하도록 변화하기 쉽다.
OpenCL Platform Model
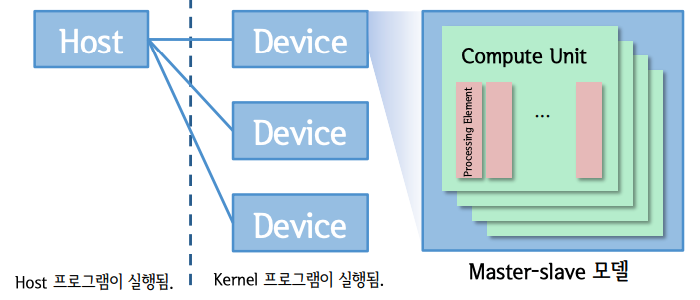
Host 는 Master 프로세서이며, Host 프로그램이 동작하는 환경이다. Host 는 입출력 또는 사용자 상호작용 등을 할 수 있도록 인터페이스 역할을 수행한다.
Device 는 Slave 프로세서 이며, OpenCL 계산 유닛이다. 즉, 커널 프로그램을 수행한다. Device 의 병렬 연산은 실제로 PE(Processing Element) 안에서 이루어진다. Device 는 CPU 혹은 GPU 등이 될 수 있다.
Terminology(핵심 용어)

Compute Device
Compute Device 는 host CPU로부터 오프로드되는 연산의 타겟이다. Command-queue 는 OpenCL 어플리케이션에서 생성되고 특정 compute device로 묶인다. compute device는 compute unite의 집합이며 OpenCL은 일반적으로 보통 GPU, 멀티코어 CPU, 멀티 코어 DSP에 해당하는 devices을 연산한다.
Compute Unit
Compute Device 는 하나 이상의 Compute Units(CU) 을 가진다. 멀티코어 디바이스에서 CU는 보통 하나의 코어와 대응된다. 하나의 work group은 CU 한 개를 실행시키고 여러 work group은 디바이스 안에 여러 CU을 병렬적으로 실행시킬 수 있다. CU는 자신만이 접근할 수 있는 로컬 메모리를 가진다.
Command Queue
Command Queue 는 host application에서 OpenCL API로 만들어진다. command-queue 는 특정한 디바이스의 컨텍스트의 특정 device에 대해 생성되어 특정한 디바이스에서 실행될 command을 가진다. 커맨드는 command queue 로 순서대로 큐잉되지만 실행될 때는 순서대로일 수도 아닐 수도 있다. 이는 command queue의 생성동안 특정되는 속성에 따라 다르다. Compute device 는 자신과 관련된 많은 command queue을 가질 수 있지만, 하나의 command queue 는 오직 하나의 compute device 와 연관되어 있다.
Kernel
Kernel 은 병렬 연산을 위한 핵심 로직이다. Heterogenous 한 기종 플랫폼 간의 높은 이식성을 위해 OpenCL C 프로그램에서 C 언어로 구현되고 OpenCL C 컴파일러로 컴파일된다. Compute Device 에서 실행된다.
커널은 __kernel 이나 kernel qualifier 로 정의된다. 커널은 command queue 를 통하여 compute device 에 인큐된다.
Context
Host 프로그램은 OpenCL 안에서 정의된 커널 객체들이 어떻게 상호 연동해야 하는지를 규정한다. 이 정책과 연산 순서를 Context 라고 한다. Context 에 포함된 것은 한 개 이상의 프로그램 객체이고 이 객체는 커널을 위한 코드를 가지고 있다.
즉, Context 는 kernel 과 command-queue, memories 을 포함하는 OpenCL 환경이다. memory object 는 같은 context 내에서 공유될 수 있다.

Work-item
Work-item 은 커널이 command queue 에 인큐될 때 인큐 커맨드가 완수되어야 하는 work-item 의 수를 명시한다. 예를 들어 enqueueNDKRangeKernel 에서는 work-item의 수는 global size argument로 명시적으로 정해진다. enqueueTask 에 대해서 work items 의 수는 1로 암시적으로 정해진다.
커널의 병렬 실행의 set은 커맨드를 통해 디바이스를 주입한다. Work item 은 CU에서 실행하는 work-group의 일부인 processing elements 로 로 실행된다. Work item은 자신의 global ID와 local ID 를 통해 같은 집합의 다른 실행들과 구분된다.
Work-group
Work-group 은 단일 CU에서 실행되는 work item 의 집합이다. Group 에서의 work item 들은 같은 커널을 실행하고 로컬 메모리를 공유한다.
Global ID
Global ID 은 work item을 특별히 구분짓는데 사용되고 커널을 실행시킬 때 정해지는 global work item 의 수로 유도된다. Global ID는 N차원 값이고 모든 차원에서 0으로 시작한다. (global dimensions 은 연산 수행의 범위를 뜻한다. )
Local ID
Local ID 은 커널을 실행시키는 work group에서 unique 한 work-item ID 을 말한다. Local ID는 N 차원 값이고 모든 차원에서 0으로 시작한다. (Local dimensions 은 workgroup 의 크기를 뜻한다. )

위 그림은Host-Programming Model이 동작하는 모습을 나타낸다. Host 에서 Function call (엄밀히 말하면 Launch kernel) 을 하여 Compute Device 에 동작을 명령한다. Host가 CPU, Device 가 GPU 일 경우 Launch kernel 이후 GPU 가 해당 동작을 수행하는 동안 CPU는 당연히 다른 작업이 가능하다.
그렇다면 OpenCL 에서는 Data-Parallelism 을 어떻게 표현할까?
Expressing Data-Parallelism in OpenCL
N 차원의 computation domain 을 정의한다. (N = 1, 2 or 3..)
N차원 도메인에서 실행의 각 독립적인 element 는 work-item 이라고 불린다.
예시로 1024 * 1024 image 을 처리한다고 하자.
Global problem 차원은 1024 * 1024.
kernel 1 개가 pixel 하나마다 실행되어서 1,048,576개의 커널이 실행된다.
void scalar_mul(int n, const float. *a,
const float *b, float *result) {
int i;
for (i=0; i<n; i++)
result[i] = a[i] * b[i];
}kernel void
dp_mul(global const float *a,
global const float *b,
global float *result) {
**int id = get_global_id(0);
result[id] = a[id] * b[id];**
}
// execute dp_mul over "n" work-itemsopenCL 로 곱셈을 병렬적으로 수행할 때는 for 문이 없는 것을 확인할 수 있다.
병렬 처리 후 동기화 시 주의할 점
💡 이 때 Global work-items 은 global 로 동기화하지 않고 독립적이어야 한다.
동기화는 하나의 workgroup 내에서 수행되어야 한다.
위 말을 보면 한국어인데 잘 이해가 가지 않는다. 실제 1024 * 1024 이미지가 아래와 같다고 가정해서 살펴봅시다.
아래 이미지에서 Global Dimensions 은 1024 * 1024 (whole problem space)
Local Dimensions 은 128 * 128 (executed together) 이다.
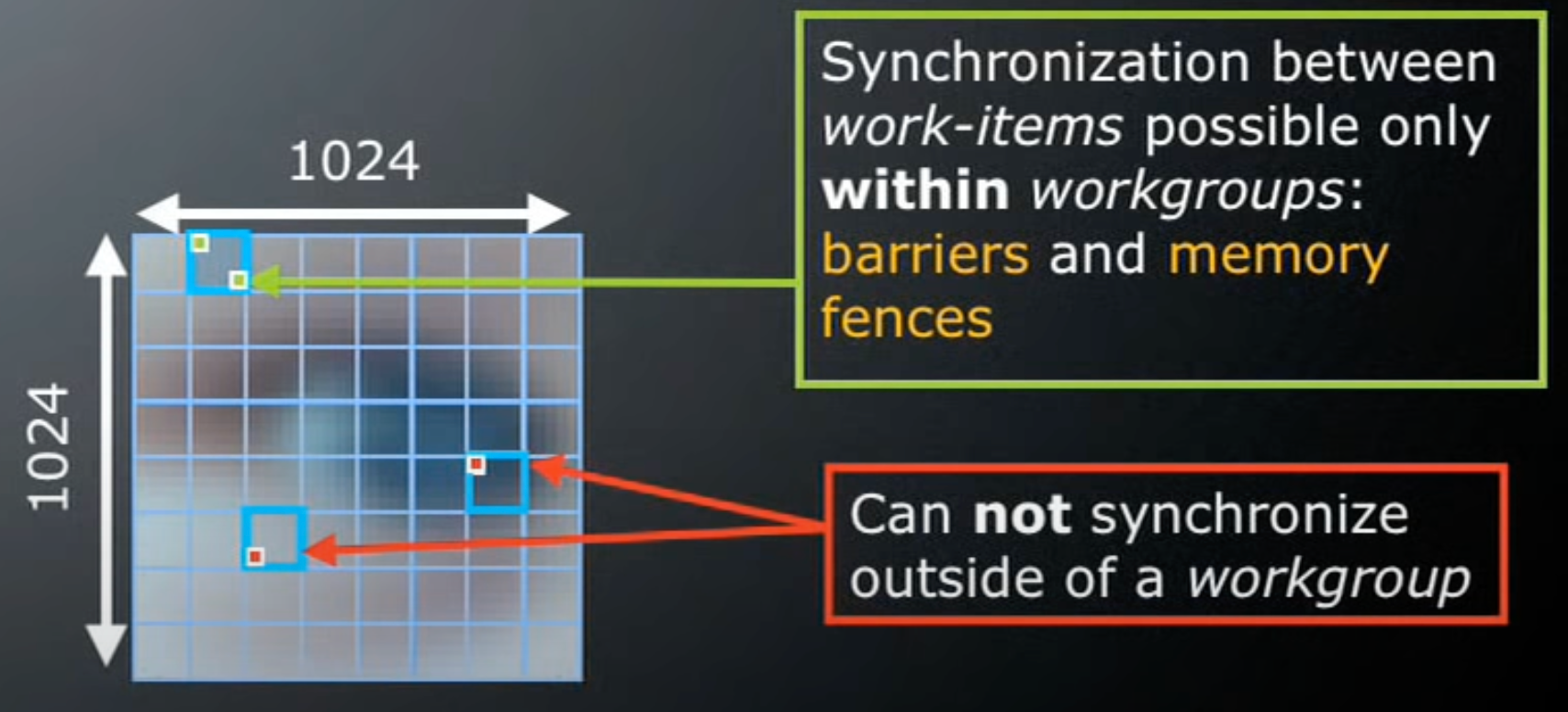
위 사진만 보면 위에 표현된 말들이 무슨 말인지 바로 알 수 있다.
각 workgroup 에서 work-items 는
barriers 을 사용하여 실행을 동기화 할수 있고
memory fences 을 사용하여 메모리 접근을 동기화할 수도 있다.
만약 정말로 전역 동기화가 필요하다면???
그 때는 커널 간의 multi-pass 알고리즘을 사용해야 한다.
Example Problem Dimensions
- 1D : 하나의 배열에 백만개의 요소라면.
- global_dim[3] = {1000000, 1, 1};
- 2D: 1920 * 1200 HD video frame이면, 230만개의 pixels 이 있다.
- global_dim[3] = {1920, 1200, 1};
- 3D: 256 * 256 * 256 volume, 167만 개의 voxels 이 있다.
- global_dim[3] = {256, 2556, 256};
위처럼 표현된다!
OpenCL Objects
OpenCL 애서 커널을 사용하는 진행 순서를 보기 전에 먼저 OpenCL Objects 을 정리합시다.
- Devices: GPU, CPU, Cell/B.E.
- Contexts: Collection of devices
- Queues: Submit work to the device
- Memory
- Buffer: Blocks of memory
- Images: 2D or 3D formatted images
- Execution
- Programs: Collections of kernels
- Kernels: Argument/execution instances
- Synchronization/profiling
- Events
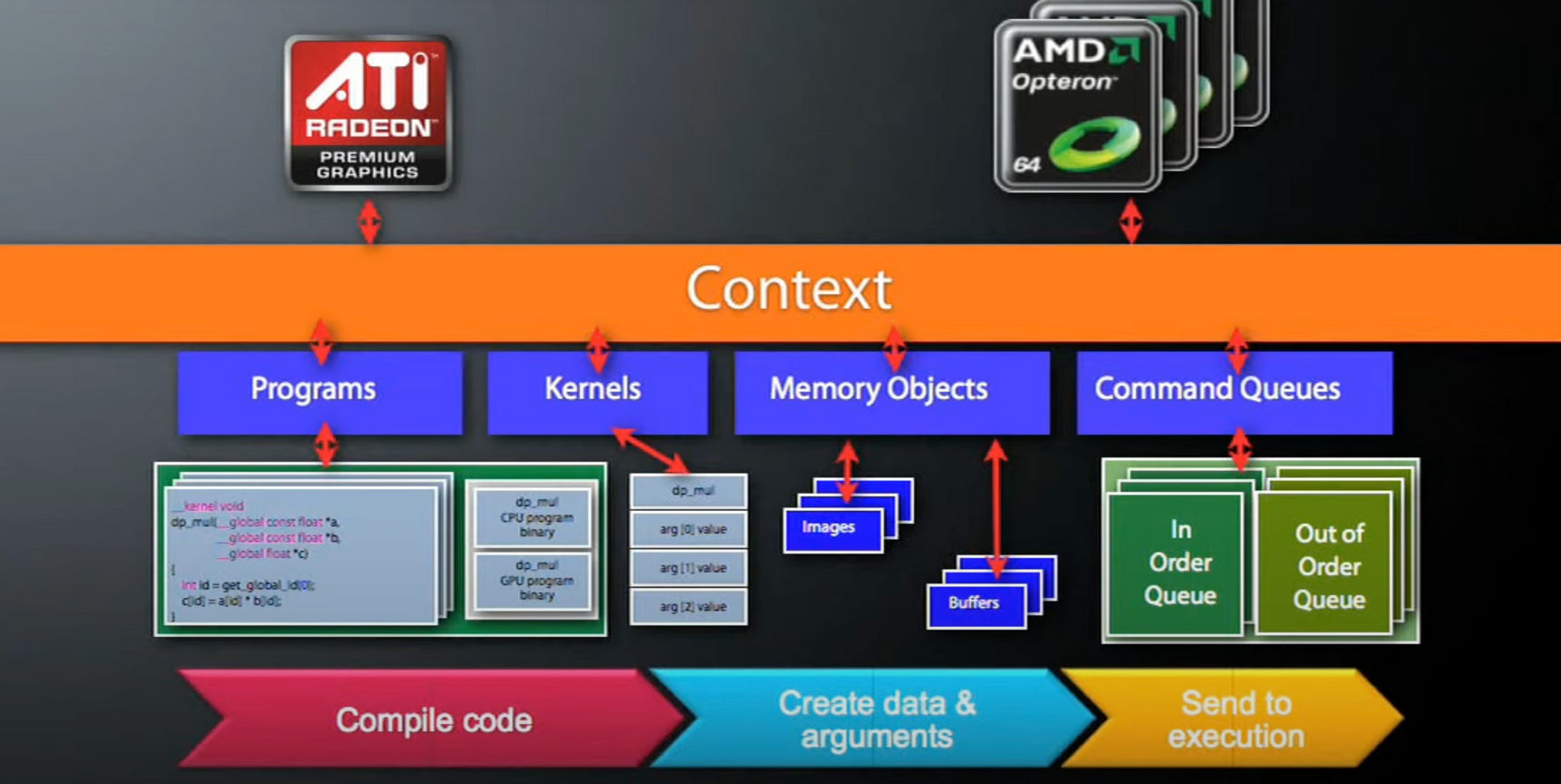
OpenCL 코드 진행 순서
1. Create OpenCL context (OpenCL Context 을 생성)
이 과정에서는 OpenCL platforms 을 정의하고 OpenCL platform 을선택한다.
cl_uint numPlatforms;
cl_platform_id firstPlatformId;
cl_context context = NULL;
// 이 예에서는 그냥 사용할 수 있는 첫번째 platform 을 선택한다.
clGetPlatformIDs(1, &firstPlatformId, &numPlatforms);
// GPU-기반 platform 에 있는 OpenCL context을 생성한다.
cl_context_properties contextProperties[] =
{CL_CONTEXT_PLATFORM, (cl_context_properties)firstPlatformId, 0};
context = clCreateContextFromType(
contextProperties, CL_DEVICE_TYPE_GPU, NULL, NULL, NULL);clGetPlatformIDs

시스템에서 OpenCL 이 동작하는 플랫폼을 찾아서 플랫폼의 ID 정보를 얻어오는 함수.
PARAMETERS
cl_unit num_entries: 호스트에 존재하는 애플리케이션이 원하는 플랫폼 수
cl_platform_id *platforms: 플랫폼 ID 가 저장될 cl_platform_id 변수의 주소 값
cl_uint *num_platforms: 플랫폼 수가 저장될 cl_int 변수의 주소 값
리턴: 함수 성공 시 CL_SUCCESS 반환.
clGetDeviceIDs
https://registry.khronos.org/OpenCL/sdk/1.0/docs/man/xhtml/clGetDeviceIDs.html
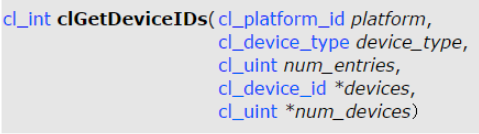
플랫폼에서 사용할 디바이스 정보를 불러오는 함수
PARAMETERS
platform: 디바이스를 포함하는 플랫폼 ID
device_type: 디바이스 형식(CPU_DEVICE_TYPE_DEFAULT/CPU/GPU)
num_entries: 불러올 디바이스 수
devices: 사용할 디바이스 정보가 저장될 저장소의 주소 값
num_devices: 불러온 디바이스 수. (NULL 이면 무시)
리턴: 함수 성공 시 CL_SUCCESS 리턴.
clCreateContext
https://registry.khronos.org/OpenCL/sdk/1.0/docs/man/xhtml/clCreateContextFromType.html

디바이스로부터 OpenCL context 을 생성한다.
PARAMETERS
properties: context property 이름 과 그에 맞는 값 리스트. 각 property 이름은 즉시 일치하는 값으로 이어진다. 지원되는 properties 의 리스트는 아래 테이블과 같다. 0 이면 리스트는 제거된다.
| cl_context_properties enum | Property value | Description |
| CL_CONTEXT_PLATFORM | cl_platform_id | Specifies the platform to use. |
num_devices: Context 에서 사용하는 디바이스 수
device_id: 디바이스 id 의 포인터
pfn_notify: 이 애플리케이션에 의해 등록된 콜백 함수. 이 context 내에서 발생하는 에러 정보를 알리기 위해 사용된다. NULL 이면 콜백함수가 등록되지 않는다.
2. Create a command-queue (Command-queue 생성)
이 과정에서는 context의 device 에 command-queue 을 생성한다.
cl_device_id *devices;
cl_command_queue commandQueue = NULL;
size_t devBufSize = -1; // size_t==unsigned int, 문자열 or **메모리의 사이즈**
// 디바이스 버퍼의 사이즈를 얻는다.
**clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, NULL, &devBufSize);**
// 디바이스 버퍼에 메모리를 할당한다.
devices = new cl_device_id[devBufSize / sizeof(cl_device_id)];
clGetContextInfo(context, CL_CONTEXT_DEVICES, devBufSize, devices, NULL);
commandQueue = **clCreateCommandQueue(context, devices[0], 0, NULL);**
clGetContextInfo

context 에 대한 Query 정보.
PARAMETERS
context: 쿼리된 OpenCL context을 명시.
param_name: 쿼리로 정보를 명시하는 열거형 constant. 값은 아래와 같다.
| cl_context_info | Return Type | Information returned in param_value |
| CL_CONTEXT_REFERENCE_COUNT | cl_uint | Return the context reference count. This feature is provided for identifying memory leaks. |
| CL_CONTEXT_NUM_DEVICES | cl_uint | Return the number of devices in context. |
| CL_CONTEXT_DEVICES | cl_device_id[] | Return the list of devices in context. |
| CL_CONTEXT_PROPERTIES | cl_context_properties[] | Return the properties argument specified in clCreateContext(orFromType). clCreateContext 로 명시된 properties 매개변수가 NULL이 아니면 properties 매개변수에서 명시된 값 리턴. 만약 NULL 이면 0. |
param_value: 쿼리된 적절한 결과가 리턴되는 메모리로의 포인터. NULL 이면 무시됨.
param_value_size: param_value 가 가리키는 메모리의 크기.
param_value_size_ret: param_value 에 의해 쿼리되는 데이터의 실제 크기
clCreateCommandQueue

특정 디바이스에 command-queue 을 생성한다.
PARAMETERS
context: 큐에 소속될 context 핸들러
device: 큐에 쌓이는 명령을 처리할 디바이스.
properties: 큐의 속성 리스트.
| Command-Queue Properties | Description |
| CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE | 설정되면 out-of-order 로 실행될지 결정한다. 아니라면 in-order 로 실행된다. |
| CL_QUEUE_PROFILING_ENABLE | 큐에서 command의 프로파일링하는 것을 가능하게 한다. |
1, 2 단계는 OpenCL infra 을 만드는 과정이다.
3. Create an OpenCL program
~~.cl 파일로부터 커널 소스 코드를 로드하고 program object 을 생성한다.
cl_program program;
std::ifstream kernelFile(fileName, std::ios::in);
std::ostringstream oss;
oss << kernelFile.rdbuf();
std::string srcStdStr = oss.str();
const char *srcStr = srcStdStr.c_str();
// 위는 커널 파일을 읽는 코드임.
program = **clCreateProgramWithSource(context, 1, (const char**)&srcStr,
NULL, NULL);**
**clBuildProgram(program, 0, NULL, NULL, NULL, NULL);**
clCreateProgramWithSource()

OpenCL 커널 소스코드로 프로그램 객체를 생성하는 함수. context 의 program object 을 생성하고 문자열배열의 소스코드를 program object로 로드한다.
PARAMETERS
context: 프로그램이 소속될 context 핸들러
count: 커널 프로그램 소스 코드의 개수
strings: 커널 프로그램 소스 코드 (소스코드를 구성한 문자열의 포인터)
lengths: 커널 프로그램 소스코드의 문자열 길이. 값이 0 이면 해당 문자열이 null 문자 로 끝남. NULL 이면 모든 문자열이 null로 끝남.
clBuildProgram()
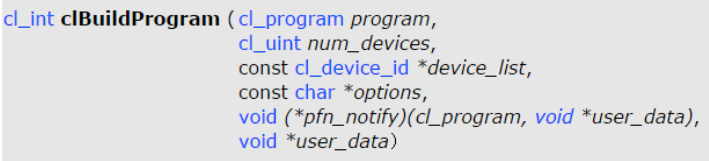
프로그램 객체의 소스코드를 program executable 로 런타임 빌드한다.
program: 소스코드를 포함하는 프로그램 객체
num_devices: 프로그램 오브젝트에 연관된 디바이스 정보 수
device_list: 프로그램 오브젝트에 연관된 디바이스 정보 리스트
options: 빌드 옵션 - 최적화, 수학관련 함수 등 빌드 옵션을 지정할 수 있다.
pfn_notify: 빌드 루틴에서 발생하는 일들을 리포트해주는 콜백 함수
user_data: 콜백 함수에 전달할 파라미터.
4. Create a kernel
cl_kernel kernel = 0;
kernel = **clCreateKernel(program, "vectorAdd_kernel", NULL);**
clCreateKernel

커널 오브젝트를 생성한다.
PARAMETERS
program: 커널을 포함하는 프로그램 객체.
kernel_name: 커널 객체에 저장할 커널 함수의 이름.
errorcode_ret: 커널 객체 생성 결과 (CL_SUCCESS 명 정상적으로 생성됨)
5. Create memory objects
kernel 로의 arguments 로서 사용되는 메모리 objects 을 생성한다.
cl_mem d_A, d_B, d_C;
float h_a[LENGHT], h_b[LENGTH], h_c[LENGTH];
d_A = clCreateBuffer(context, CL_MEM_READ_ONLY,
sizeof(float) *LENGTH, NULL, NULL);
d_B = clCreateBuffer(context, CL_MEM_READ_ONLY,
sizeof(float) *LENGTH, NULL, NULL);
d_C = clCreateBuffer(context, CL_MEM_READ_ONLY,
sizeof(float) *LENGTH, NULL, NULL);clCreateBuffer
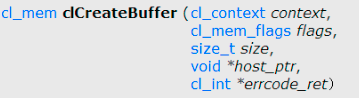
커널이 동작할 때 필요한 처리 대상인 배열 등이 데이터가 저장되는 메모리 객체를 생성하는 함수.
PARAMETERS
context: 메모리가 소속될 context 핸들러
flags: 메모리 객체 생성 옵션.
size: 메모리 객체가 차지하는 공간
host_ptr: 상호작용할 Host 배열의 포인터
https://registry.khronos.org/OpenCL/sdk/1.0/docs/man/xhtml/clCreateBuffer.html
4, 5, 6은 Kernel infra 을 만드는 과정이다.
6. Write the input from the host
clEnqueueWriteBuffer(cmdQ,
d_A, // 디바이스 메모리
CL_TRUE, // blocking write
0,
ARRAY_SIZE * sizeof(float), // write 되는 데이터의 크기
h_A, // host memory 의 어디서 데이터를 작성하는지
0, NULL, NULL)clEnqueueWriteBuffer
https://registry.khronos.org/OpenCL/sdk/1.0/docs/man/xhtml/clEnqueueWriteBuffer.html

Host 메모리에서 buffer object(디바이스 메모리) 로 커맨드를 인큐해서 write하는 함수.
호스트 메모리에서 디바이스 버퍼 개체에 쓰기 위한 Enqueue 명령입니다.
PARAMETERS
command_queue: write command 를 추가할 커맨드 큐
buffer: 큐에 추가할 buffer(메모리) 객체
blocking_write: write 동작을 block 할지. CL_TRUE 이면 포인터가 가리키는 데이터를 복사하고 write 동작을 command-queue 에 enqueue 한다.
offset: write 할 buffer 객체의 offset(변위). 바이트 단위임.
cb: 복사 대상 배열의 크기
ptr: 복사 대상 배열의 주소 값
7. Set the kernel arguments
clSetKernelArg(kernel, 0, sizeof(cl_mem), &d_a);
clSetKernelArg(kernel, 1, sizeof(cl_mem), &d_b);
clSetKernelArg(kernel, 2, sizeof(cl_mem), &d_c);
clSetKernelArg
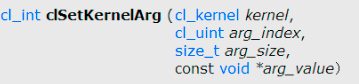
커널에서 처리할 데이터가 저장되어 있는 메모리 객체 정보를 커널에 추가하는 함수.
PARAMETERS
kernel: 메모리 객체를 추가할 타겟 커널 객체
arg_index: 추가할 메모리 객체의 인덱스
arg_size: parameter 의 크기 (메모리 객체의 크기)
arg_value: parameter 의 값 (메모리 객체)
8. Queue the kernel
디바이스에서 커널을 실행하기 위해 커맨드를 enqueue 한다.
size_t globalWorkSize[1] = { N }; // vector length
size_t localWorkSize[1] = {256};
**clEnqueueNDRangeKernel(cmdQ, kernel, 1, NULL, globalWorkSize,
localWorkSize, 0, NULL, NULL);**
만약 2-dimensional mapping( 2차원 매핑)이라면
size_t globalWorkSize[2] = { M, N };
size_t localWorksize[2] = {32, 8};
**clEnqueueNDRangeKernel(cmdQ, kernel, 2, NULL, globalWorkSize,
localWorkSize, 0, NULL, NULL);**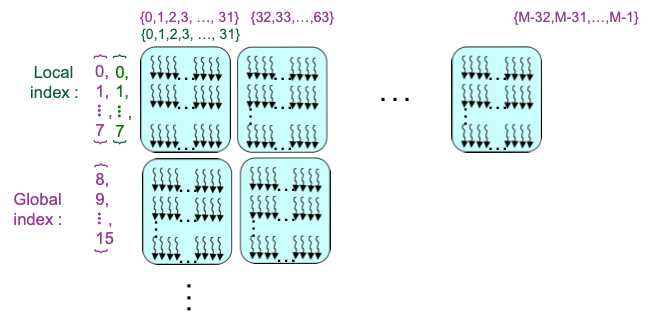
clEnqueueNDRangeKernel
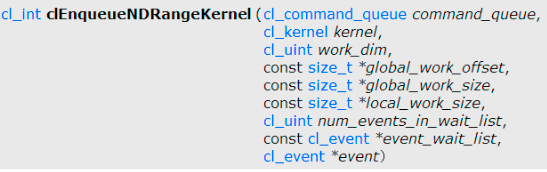
디바이스에서 커널을 실행하기 위해 커맨드를 enqueue 한다.
PARAMETERS
command_queue: 커널 객체를 추가할 타겟 커맨드 큐
kernel: 큐에 추가할 커널 객체
https://registry.khronos.org/OpenCL/sdk/1.0/docs/man/xhtml/clEnqueueNDRangeKernel.html
9. Read the output back to the host
clEnqueueReadBuffer(cmdQ
d_c, // 디바이스 메모리
CL_TRUE, // blocking read
0,
ARRAY_SIZE *sizeof(float), // 읽어지는 데이터의 크기
h_c, // 호스트 메모리
0,
NULL,NULL);clEnqueueReadBuffer

메모리에 저장되어 있는 데이터들을 읽어서 Host 배열에 저장하는 함수.
PARAMETERS
command_queue: 커널 객체를 추가할 타겟 커널 큐.
buffer: 큐에 추가할 커널 객체
cb: 복사 대상 배열의 크기
ptr: 복사 대상 배열의 주소값
6, 7, 8, 9 는 Launch the kernel 의 과정이다.
마지막으로 오브젝트를 해제하는 코드까지 알아보자.
ret = clFlush(command_queue);
ret = clFinish(command_queue);
ret = clReleaseKernel(kernel);
ret = clReleaseProgram(program);
ret = clReleaseMemObject(memobj);
ret = clReleaseCommandQueue(command)queue);
ret = clReleaseContext(context);
cFlush - 큐에 잔존하는 객체들을 비우는 함수
clFinish - 큐에 있는 모든 객체들이 비워질 때까지 대기하고 있는 함수
clRelease - 객체가 점유하고 있는 자원을 리턴하는 함수
실습
실습은 컴퓨터(Linux)에서 한백전자의 타겟보드를 연결하고 해당 타겟 보드에 크로스 컴파일을 하는 환경이다. 한백전자 타겟보드는 안드로이드 OS 여서 ADB 을 사용하였고 컴파일러는 Compiler(arm-linux-androideabi-gcc) 이다.
또 OpenCL Headers 와 OpenCL Library (libOpenCL.so 와 libGLES_mali.so) 을 준비한다.
sudo apt-get install gcc-arm-linux-androideabi
실습을 진행하기 전 필요한 라이브러리와 헤더를 다운로드받아 작업환경을 구축하였다.
Vadd.c 소스 파일
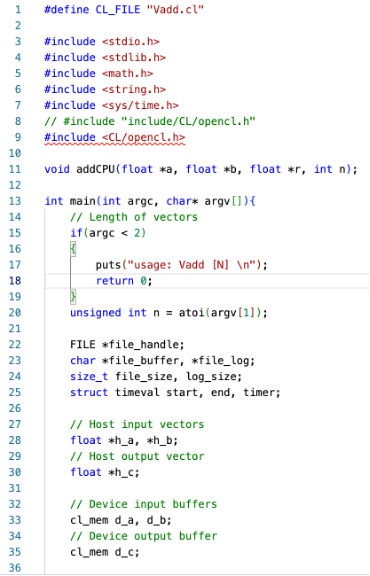
Main 함수에 인자로 argv 는 문자형 배열이며 첫번째 element 는 항상 주소가 들어간다. Argc 는 argv 의 수로 argc < 2 라는 것은 우리가 입력한 argv 가 없다, 즉 입력 가능한 상태이다. atoi 함수를 활용해서 argv 첫번째 값을 정수 n 으로 받는다. 이 때 n은 벡터의 크기를 사용자로부터 입력받고 이는 kernel 의 개수가 될 것이다.
File_handle 과 *file_buffer, *file_log, file_size, log_size 는 .cl 파일을 읽는데 필요한 변수들이다. 그 외에 코드에서 사용할 여러 변수들을 선언해준다.
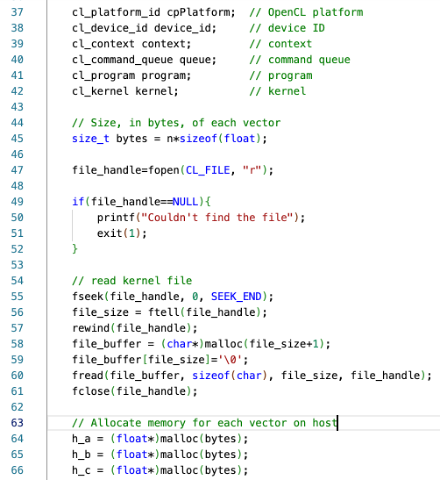
OpenCL 을 사용하는데 필요한 정보 OpenCL platform, device Id, context, command queue, program, kernel 을 선언해준다. 앞으로 Vadd.cl 이라는 이름의 kernel 파일을 만들 것인데 이 kernel 파일을 읽는다.
각 벡터의 크기를 bytes 라는 변수에 저장한 후 해당 크기만큼 host 에서 각 vector을 위한 메모리 공간을 할당한다.
// 파일을 가지고 스트림을 형성한다.
FILE *fopen(const char *filename, const char *mode)
const char *filename: 파일의 이름
const char *mode: 어떤 형태로 스트림을 형성할지 결정.
우리는 CL_FILE(Vadd.cl) 을 데이터를 읽는 모드로 스트림을 만든다. 이를 file_handle 에 저장한다.
// 파일의 읽기 쓰기 위치 이동 함수.
int fseek(FILE *stream, long offset, int whence)
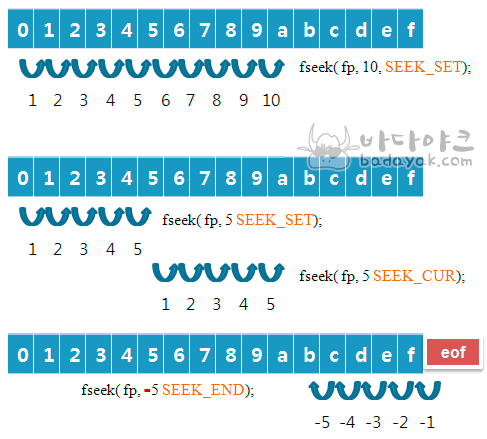
FILE *stream: 대상 파일 스트림
long offset: 이동할 바이트 수
int whence: 시작 지점
리턴: 성공 → 0. 오류 → -1
위에서는 file_handle 파일을 SEEK_END(파일의 끝)에서부터 읽는다.
https://badayak.com/entry/C언어-파일-읽기·쓰기-위치-이동-함수-fseek
// 파일 포인터의 위치를 알아온다. 우리는 위에서 이것으로 파일의 크기를 알아올 수 있다.
long int ftell(FILE *stream)
// stream 의 파일 위치 포인터를 시작위치로 옮긴다.
void rewind(FILE *stream)
그 후 알아낸 file의 크기 + 1 만큼 메모리에 공간을 file_buffer 라는 이름으로 할당한다. 해당 메모리의 마지막 위치는 null문자 /0 으로 설정한다.
// 파일로부터 데이터를 읽는다.
size_t fread(void *ptr, size_t size, size_t count, FILE *stream)
*ptr: 파일에서 읽어온 것을 저장할 block 을 가리키는 포인터
size_t size: block 의 크기
size_t count: block 의 개수
FILE *stream: 타겟 파일.
위에서는 file_buffer 에 읽어온 것을 저장한다.
후에 fclose 라는 함수로 file_handle 의 메모리를 해제한다.

Host에 있는 vector 를 반복문을 통해 랜덤으로 초기화한다. srand(time(NULL)) 하게 되면 1970년부터 현재까지의 시간을 시드로 하여 랜덤 값을 설정하게 된다. 즉, 프로그램이 돌아갈 때마다 시드값도 변한다.
Local size 와 global size 을 정한다. 이 때 global size 가 local size 의 정수배가 되지 않을 때를 고려하여 간단한 연산을 수행한다.
우리는 platform 을 하나만 만들어서 사용하므로 platform 을 1번으로 맞춰준다. Device의 id을 저장한다. context, command-queue, program 객체를 생성한다. 생성한 program 객체로 exe 파일을 빌드하고 “vecAdd” 라는 이름의 kernel object 을 만든다

Device memory 에 커널이 처리할 메모리 객체 input/output array 을 만든다. 이것으로 우리 data set 을 작성한다.
Compute kernel 에 argument 을 설정하고 gettimeofday 라는 api을 사용하여 이 코드가 수행되는 시점을 start의 주소값에 저장한다. Data set 의 전체 범위에 kernel 을 실행시킨다. Command-queue 의 수행이 끝날 때 까지 기다린 후 device로부터 결과를 읽는다.
여기까지 수행한후 다시 gettimeofday api 을 사용하여 end에 시점을 저장한다. End 에서 start 을 빼면 kernel의 수행이 완료되는 데 걸리는 시간을 구할 수 있다.
Kernel 의 동작이 종료되고 나서는 OpenCL resources 을 release 해주어야 한다.
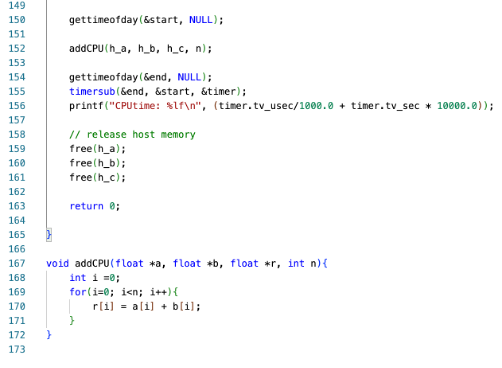
그 후 addCPU 라는 함수를 실행하여 똑같이 전체 함수의 동작이 완료되는 데 걸리는 시간을 구한다. 이렇게 해서 우리는 addCPU 라는 함수의 동작 완료에 걸리는 시간과 Vadd.cl 소스 파일의 kernel 의 동작 완료 시간을 비교할 수 있다.
vecAdd 커널 파일 (OpenCL kernel)
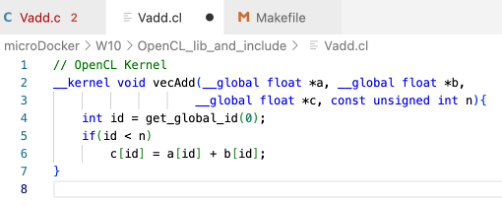
OpenCL 로 수행되어야 하는 메서드이기 때문에 __kernel 이라는 identifier 을 준다. Get_global_id 의 argument 을 0으로 설정하여 우리의 addition 의 dimension 1차원을 설정한다.
이제 vAdd.c 에서 이 커널이 실행될 것이다.
**get_global_id**
// 차원에 맞는 work-item ID 값을 리턴한다.
//argumnet 로는 0 부터 원래 차원의 -1 까지 가능하다.
size_t get_global_id(uint dimindx)Makefile
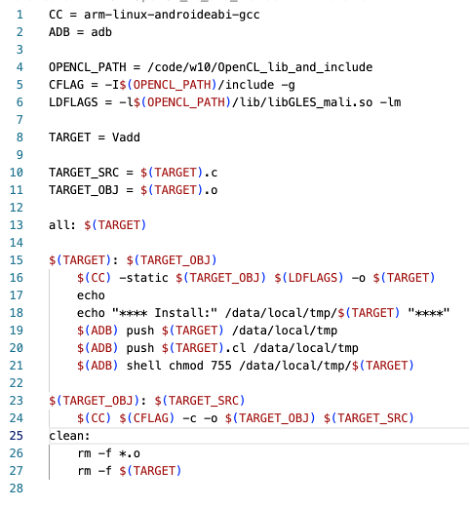
컴파일러로 androideabi 을 사용하고 OPENCL_PATH에 openCL파일이 있는 경로를 지정했다. 7번째 줄 아래는 이전의 실습에서 해왔던 push하고 권한을 주는 코드이다.
코딩은 docker 환경에서 사용했는데 이 때 docker 에서는 디바이스 포트에 adb device 가 연결되었는지 인식을 하지 못하므로 adb push 부터 adb shell 관련 명령어는 mac 의 터미널에서 따로 진행했다.
실습결과
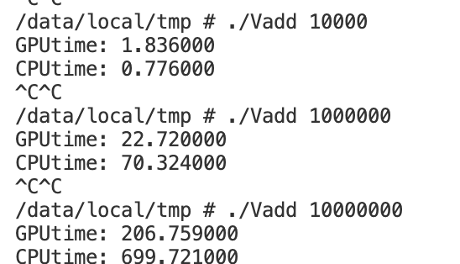
Adb shell 을 통해 adb 환경에서 Vadd 파일을 실행했다. 10,000 을 입력했을 때는 CPU 로 Host 에서 실행했을 때의 시간이 오히려 약 2.3 배정도 더 빨랐지만 수가 1,000,000 으로 입력했을 때 GPU 을 platform 으로 구동했을 때 3배정도, 10,000,000 으로 입력했을 때는 3.4 배정도 빠르게 완료되는 것을 확인할 수 있었다.
Table 1 CPU, GPU 연산 시간과 시간 이득
연산량이 증가함에 따라 GPU 가 CPU 보다 연산속도 면에서 큰 효율을 보여준다.
아래는 깃허브 링크이다. 당연히 Makefile 에서 경로를 수정해주어야 한다.
'CrossCompile' 카테고리의 다른 글
| Gaussian Blur (OpenCL 사용, GPU 에서) (1) | 2022.11.12 |
|---|---|
| Gaussian Blur (OpenCL 없이 CPU 에서 실습) (0) | 2022.11.12 |
| Android NDK& JNI 리눅스 디바이스 드라이버를 사용하여 개발하기 (0) | 2022.11.11 |
| Linux Device Driver (LED) (0) | 2022.11.11 |
| Cross-compile & Linking & Make (2) | 2022.11.11 |